Publishing
The concept of publishing on the web has evolved as the web's ecosystem has enlarged and diversified, and as the capabilities of browsers and the web standards that they implement have developed. There is no single definition of what publishing on the web means. Instead, there are a number of activities that could be viewed as publication or distribution in a legal sense. This section describes some of these activities and how they work.
Hosting
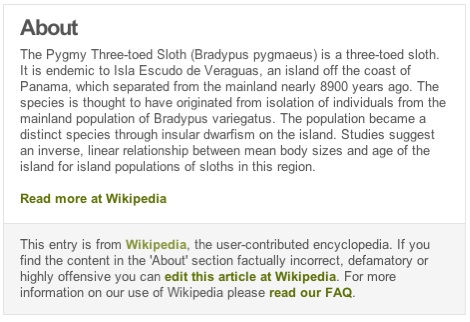
The basic form of publication on the web is hosting. A server hosts a file if it stores the file on disk or generates the file from data that it stores, and that file did not (to the server's knowledge) originate elsewhere on the web.
A browser makes a request to a hosting server for a file. The hosting server responds with the content of that file, which the browser stores in a local cache and displays to the user.
The presence of data on a server does not necessarily mean that the organisation that owns and maintains the server has an awareness of the presence of the data or its content. Many websites are hosted on shared hardware that is owned by a service provider that stores and serves data at the direction of controlling individuals and organisations which determine the data they provide on the site. Because of this, multiple servers may host the same file at different locations.
There are many different types of service provider. Some exercise practically no control over the software and data that they host, merely providing a base platform on which code can run. Others may focus on particular types of content, such as images (e.g. Flickr), videos (e.g. YouTube) or messages (e.g. Twitter). Also, there may be many service providers involved in the publication of a particular file on the web: some providing hardware, others providing different kinds of publishing support.
Some service providers automatically perform transformations on material that they host, as a service, such as converting to alternative formats, clipping or resizing, or marking up text. When they sign up to a service, controllers explicitly or implicitly enter into an agreement with the service provider that grants them a license to perform transformations on the material which they upload.
Service providers that host particular types of material often employ automatic filters to prevent the publication of unlawful material, but it is impossible for a service provider to detect and filter out everything that might be unlawful.
To add to the complexity of this area, it is possible for each of the following to be in different jurisdictions:
- the individual or organisation who controls the data
- the service provider(s)
- the physical servers that host the data
and be controlled by different laws and conventions.
Caching and Relaying
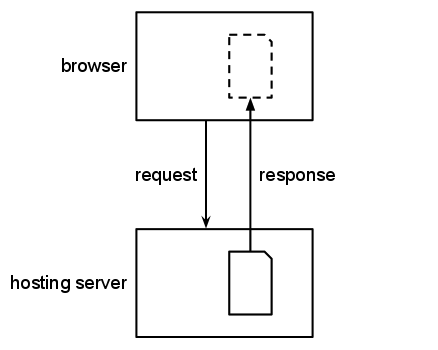
Some servers provide access to files that are hosted
elsewhere on the web: on an origin server that
holds the original version of the file. These files might be
stored on the server and provided again at a later time
(a caching proxy in this document), or might
simply pass through the server in response to a request
(a relaying server in this document).
A browser requests web content from a server; the
caching poxy responds with content that it has
fetched from an origin server.
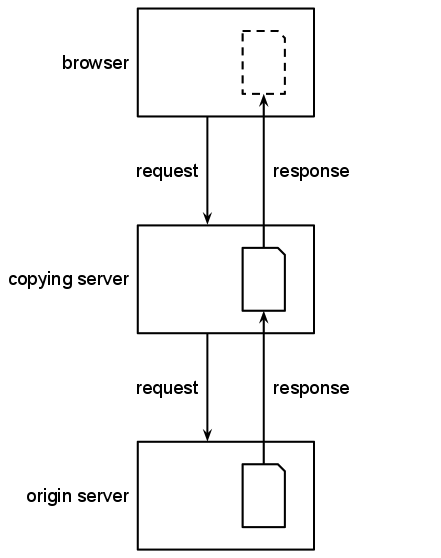
It is often impossible to tell whether a server is providing a stored response or whether it has made a new request to the origin server and is serving the results of that request. Servers commonly store the results of some requests and not others, acting as a caching proxy some of the time and as a relaying server the rest.
In both cases, the file the caching or relaying server provides might be different from the original web content that was accessed from the origin server. For example:
- Links within HTML content might be rewritten so that they point to content that is also served by the caching proxy.
- Javascript and CSS files might be combined and compressed to provide speedier access.
- Banners might be added within an HTML page to highlight that the page is a copy of an original from somewhere else.
- Content might be compressed or converted to different formats.
- Wholly new content might be created that bring together information from multiple different sources.
Caching and relaying servers are extremely useful on the web. There are four main types of caching and relaying servers discussed here: proxies, archives, search engines and reusers. The distinctions between them are summarised in the table below.
| proxy | archive | search engine | reuser | |
|---|---|---|---|---|
| purpose | increase network performance | maintain historical record | locate relevant information | better understand information |
| refreshing | based on HTTP headers | never | variable | based on HTTP headers |
| retrieval | on demand | proactive | proactive | usually on demand |
| URI use | usually uses same URI | uses new URI | uses new URI | uses new URI |
Archives
Archives aim to catalog and provide access to some web content to provide an on-going historical record. They use crawlers to fetch pages and other web content from the portion of the web that they cover, and store them on their own servers, along with metadata about the pages, including when each was retrieved. They then may provide access to the stored copies of the web content at particular historical dates, enabling people to see how pages used to appear.
Archives are often run by institutions that have a legal mandate and responsibility to keep a historical record, such as a legal deposit. Although their primary purpose is long term record-keeping, they often make this material available online as well. They might restrict access to the data for a period of time after it is collected, for security or privacy reasons, and may respond to legally-backed removal requests. Users might use archives for research, but also to access information that has otherwise been removed from the Web.
When they are made available to the public, archived pages are often distinguishable by end users from the original page using banners placed within the page or having the original page appear within a frame. The links (both to other pages and to embedded web content such as images) are usually rewritten so that when the user interacts with the page, they are taken to the version of the linked web content at the same point in time. "Dark archives" do not make their content available to the public.
Search Engines
Search engines aim to catalog and analyze as many web pages as they can, so that they can direct users to appropriate information in response to a search. They use crawlers to fetch pages and other web content from the web, analyse them and store them on their own servers to support further analysis.
Search engines are mostly interested in indexing web content and providing links to them rather than in the content itself. They may or may not copy the page itself, but they always store metadata about the page, derived from the information in the page and other information on the web, such as what other pages link to it.
Search engines play an important role in the web by enabling people to find information, including that which would otherwise be lost or is temporarily unavailable. When a user views a stored page from a search engine, it is usually obvious both that the search engine is involved (from the URI of the page and from banners or framing), that the content originally came from somewhere else, and where it came from. The links within the page are not usually rewritten.
Reusers and Aggregators
A server that is a reuser fetches information from one or more origin servers and either provides an alternative URI for the same page or adds value to it by reformatting it or combining it with other data. Good examples are the BBC Wildlife Finder, which incorporates information from Wikipedia, Animal Diversity Web and other sources or triplr.org, which converts data from one format to another as a service.
A browser requests content, which is constructed by the reusing server requesting information from two origin servers
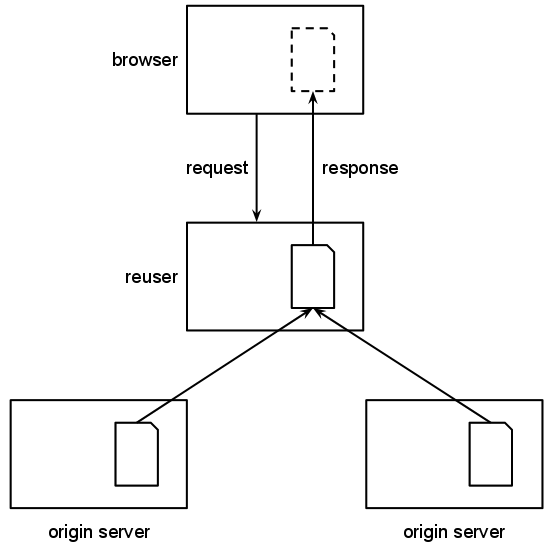
Reusers that do not change the information from the origin server may be used to simplify access to the origin server (by mapping simple URLs to a more complex query) or to provide a route around gateways or the same-origin policy (as servers are not limited in where they access web content from).
Since reused information is, by design, seamlessly integrated into a page that is served from the reuser, people viewing that page will not generally be aware that the information originates from elsewhere. The URIs used for the pages will be those of the reuser. Licenses on the material may require attribution and even when it doesn't, it is good practice for reusers to indicate where the material originates.
Including
A web page written in HTML may include other web content,
such as images, video, scripts, stylesheets, data and other
HTML. The HTML in a web page refers to this external web
content using markup. For example,
an <img> element uses
the src attribute to refer to an image which
should be shown within the page. Material that is included
within a web page may appear to be a hosted copy to the user
of a website, but in fact may come from somewhere else,
entirely outside the control of the owner of the web
page.
A browser requests a file from a server; instructions in the page tell the browser to request other web content from a different server
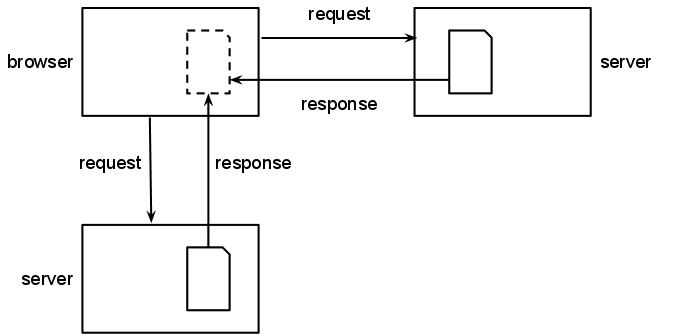
HTML supports several different mechanisms for including external web content in a web page but they all work in essentially the same way. When a user navigates to a web page, the browser automatically fetches all the included web content into its local cache and executes them or displays them within the page.
Inclusion is different from hosting, copying or disseminating a file because the information is never stored on, nor passes through, the server that hosts the web page doing the including. As such, although the included web content is an essential component of the page to make it appear and function as a whole, the server of the web page does not have control over content which may change without its knowledge.
Inclusion Chains
When scripts or HTML are included into web pages, the included content may itself include other content (which may include still more and so on). The author of the original web page can choose what content it wants to include, but does not have control over the choice of the subsequently included content. The publishers of included content might change the content at any time, possibly without warning. This has been used to include third-party images without permission, or to substitute the image with something distasteful or to redirect to a link that performed an unintended action on the user's behalf; see Preventing MySpace Hotlinking.
Hidden Requests
Some of the web content that is used within a page may be invisible to the user. An example is a hidden image that is used for tracking purposes: each time a user navigates to the page, the hidden image is requested; the server uses the information from the request of the image to build a picture of the visitors to the site.
This facility can be used for malicious
purposes. An <img> element can point to
any URI (not just an image) and causes a GET request to
that URI. If a website has been constructed such that GET
requests cause an action to be carried out (such as
logging out of a website), a page that includes this
"image" will cause the action to take place.
Linking
Linking is a fundamental facility on the web. In fact, it has
been argued that linking is what makes the Web the Web. HTML pages
can include links using the <a> element to other
pages on the web with the href attribute
holding the URI for the linked page. Some of the
links may be to be pages from the
same origin; while others will
be cross-origin links to pages on
third-party's sites that hold related information.
A browser requests content from a server; instructions in the page link to other content, but the browser does not retrieve that content until told to do so
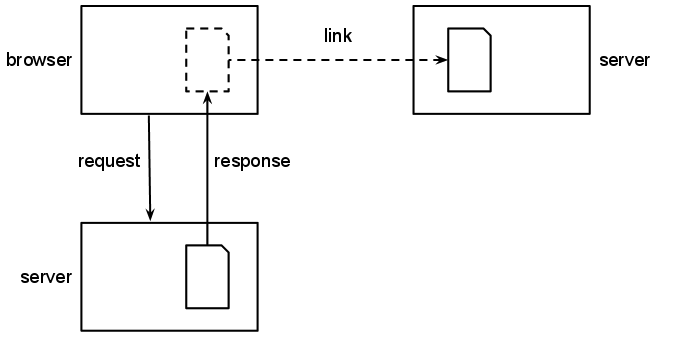
A user can usually tell where a link is going to take them
prior to selecting it by
"mousing over" it or after the link is selected through the
status bar in the browser, although some links are
overridden by onclick event handling that takes
them to a different location. Some websites, such as
Wikipedia, use icons to indicate whether a link is a
cross-origin link or whether it will take a user to a page on
the same server. The use of interstitial pages or dialog
boxes which warn the user they are about to leave the site
in question can obscure the eventual destination of the
link.
Linking Out of Control
Traditionally, a user must take a specific action in order to navigate to the linked page, such as by clicking on the link or selecting it with a keystroke or a voice command. In these cases, the linked page cannot be accessed without the user's knowledge and consent although they may not know where they will eventually end up.
Some sites use elaborate means to obscure whether a link is followed by the user. For example:
- Browsers can be made to navigate to another page using scripted navigation, which may simply run automatically (navigating the user to another page after a period of time, for example) and can hide the location of a link, such that users don't know where they will be navigating to. The HTML5 history API [[HTML5]] enables a script to change the address bar, which can mean that the address bar does not reflect the actual location of the page (although this use is limited to locations that have the same origin as the original page).
-
Browsers might pre-fetch web content that seems
likely to be visited next, so that the target page is
loaded more quickly when the user accesses it. A page
can indicate which links should be pre-fetched using
the
prefetchlink relation in a link. For example, a page might indicate that the first result in a list of search results should be fetched before the user actually navigates the link.