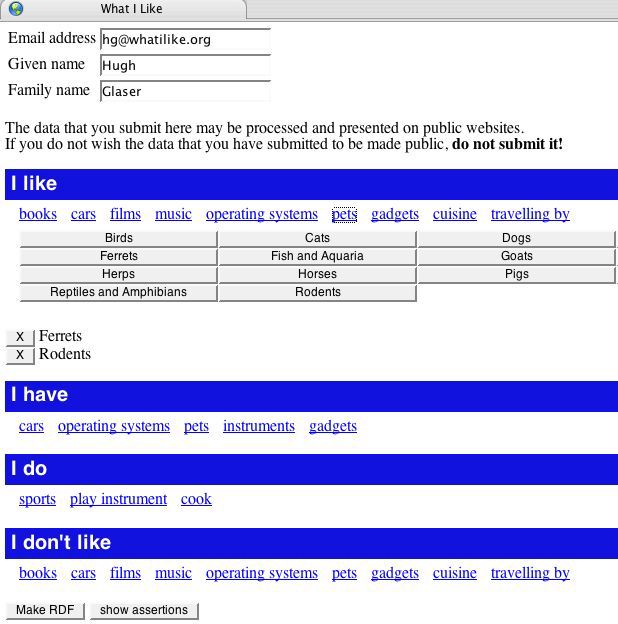
Figure 1 - Web-based interest input form.
FoaF has been a phenomenally successful activity. Individuals around the world have generated more ontologically-powered metadata, possibly by several orders of magnitude, than any other activity or tool.
FoaF is primarily fuelled by the excitement of people who are pleased to publish facts about themselves in a form that allows other people and tools to process them.
FoaF publishes against a fixed ontology, to which many extensions exist that allow virtually any information about oneself to be coded.
FoaF primarily enfranchises people who understand what is happening; this is because the tools to build FoaF descriptions are generally rather limited.
The utilities that use the FoaF descriptions are restricted because they can only use FoaF data.
It is interesting to explore what might be considered a next step.
How might we allow a more fluid ontological framework?
How would we enfranchise people who understand less about what is happening, against a more fluid ontological framework?
How do we simply encourage people to produce even more metadata?
We start with the need to gather some metadata being identified. It might be FoaF data, details of attendees for a workshop, papers at a workshop, peoples pets, or members' tastes in films for a film club.
The need arises to determine what additional information users are willing to publish. One source of focus for this, is to think back to the early days of the World Wide Web, when early adopters published web sites on their own, about themselves, with no particular goal in mind. While this kind of publishing seems trivial and vacuous, it serves to generate a lot of interest as well as enfranchise more people.
The first step is to generate some configuration data, which consists of an ontology (RDFS+RDF) and some details of exactly what to collect. Starting sources for such data are sites such as the Open Directory Project (dmoz.org), commercial sites such as Amazon (music, films) and review sites such as restaurant-guide.com (cuisine).
From then on the process is automatic. From the configuration data two objects are generated. The first is a web form that allows the data subjects to enter the data. The second is a web site that allows users to explore the data that has been provided. Both of these are specialised towards the application under consideration.
The data entry web form (Figure 1) provides a simple interface for creating RDF according to the original ontology. This RDF (Figure 2) can then be saved by the user to publish themselves and/or published by the data gatherer.
Figure 1 - Web-based interest input form.
<?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE rdf:RDF [ <!ENTITY rdfs '"http://www.w3.org/2000/01/rdf-schema#'> <!ENTITY rdf '"http://www.w3.org/1999/02/22-rdf-syntax-ns#'> <!ENTITY wil '"http://whatilike.org/ontology#'> <!ENTITY FoaF '"http://xmlns.com/FoaF/0.1/'> ]> <rdf:RDF xmlns:rdfs='&rdfs;' xmlns:rdf='&rdf;' xmlns:wil='&wil;' xmlns:FoaF='&FoaF;'> <rdf:Resource rdf:about="mailto:hg@whatilike.org"> <FoaF:name>Hugh Glaser</FoaF:name> <FoaF:givenName>Hugh</FoaF:givenName> <FoaF:familyName>Glaser</FoaF:familyName> <wil:likes rdf:resource="http://dmoz.org/Recreation/Pets/Ferrets/" /> <wil:likes rdf:resource="http://dmoz.org/Recreation/Pets/Rodents/" /> </rdf:Resource> </rdf:RDF>
Figure 2 - Generated RDF data.
The data explorer web site (Figure 3) allows users and gatherers to see what they put in, and perform some simple exploration of the data. In this example the people can be clicked upon, showing what they like and dislike, and the subjects can be clicked, to see who likes or dislikes them.
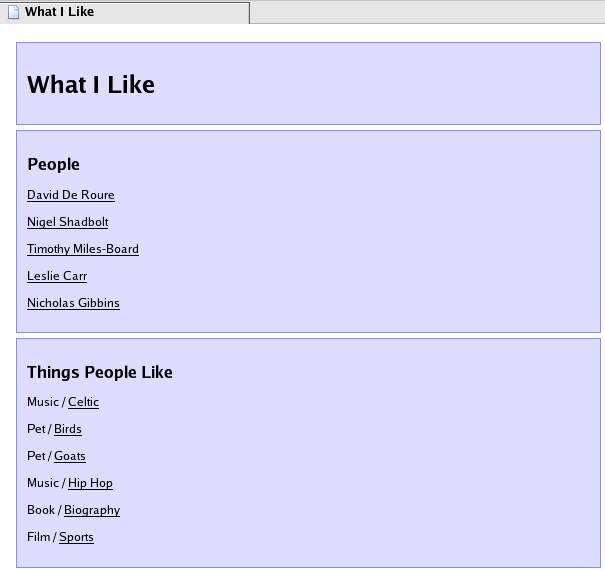
Figure 3 - Data explorer web site, allowing users to explore what people like, and what is liked by people.
The RDF that is gathered can then be used, along with the original ontology, in the required way.
We have thus cosntructed a system that provides the construction of an internally consistent metadata-gathering activity.
We believe this system has a number of other benefits. It is relatively easy to drive, making such data-gathering possible by those who are not necessarily au fait with the details of Semantic Web technologies. It is very low cost in maintenance, as there is only a single source of the forms, which can be updated and corrected by rebuilding from the configuration data. Because it is easy to use external classification systems, the URIs used by the system can indicate directly where useful connections can be made.