Tom Croucher
Human Computer Systems Group, University of Sunderland
School of Computing and Technology,
Sir Tom Cowie Campus, St Peter's Way
Sunderland, SR6 0DD
tom.croucher@sunderland.ac.uk
Abstract: Modern e-learning systems are moving toward a state where assertions about e-learning content can be made in such a way that learners are given the content that is most appropriate for them. As such it is important that the assertions on that content be made by trusted individuals. This paper discusses ways for allowing individuals to make different types of assertions and how a person's assertions may have the potential to affect the overall assertions of the system. It examines the use of the Friend of a Friend (FOAF) specification as a framework and extending the FOAF Trust model for a more generic system. This paper also introduces a new technical model of trust. This generalised model adds a level of abstraction from the previous models of trust used with FOAF to allow for the application of trust ratings to resources which are not representations of people.
A major goal in modern e-learning systems is to adapt to the individual traits of learners, their preferences and needs. This non-trivial task is dealt with by associating metadata with content that denotes the properties of that content. These properties can relate to many different aspect of the content, from from its display formats to it's appropriateness for learners with specific disabilities. These properties are diverse and rely on formal grammars to describe them. Groups such as International Standards Organisation (ISO) and the IMS Global Learning Consortium have produced formal vocabularies to describe aspects of content which relate to e-learning environments. However, such vocabularies, while highly appropriate and tuned to e-learning, require specialised systems knowledge. This means that the addition of metadata requires expert domain knowledge.
In an e-learning system with large amounts of content, finding experts with the skills to create the appropriate metadata for content is problematic. With the sheer volume of material, the frequency of updates and diversity of skills and styles exhibited by content creators the resources required to keep metadata correct, complete and current are prohibitive. However, the size of the system also presents a solution. The delivery of appropriate content is a two-sided negotiation. It relies on both the system having the appropriate metadata to describe the content and the user agent having a profile of the user's needs and a record of their current preferences. These are used to negotiate the content delivered. This means that within the framework of an e-learning system we have users who have been formally classified by expert assessors in to categories defining their needs. This builds the foundation of a peer review system of assessment rooted in profiled groups.
While having a review system which uses knowledge about individuals to allow them to contribute in their areas is ideal, there are also privacy issues involved. E-learning involves several groups for whom privacy is of the utmost importance, namely minors and people with disabilities who may not wish to share information, possible of a medical nature, with others. Also, as with any rating system, and as in the application of trust from one individual to another it is important to use a mechanism to anonymize the delivery of these rankings for the sake of social etiquette.
In this paper we will be investigating a system to rate the accessibility properties of content in an e-learning environment. While many properties could be looked at accessibility provides an initial platform upon which a more generalized system could be developed. The inferences that can be drawn from these ratings will be examined and suggestions for their application will be made. The Friend of a Friend (FOAF) specification [Brickley, Miller 2004] will be proposed to encapsulate a number of pieces of information connecting users, content and content metadata together.
While e-learning systems provide powerful solutions to describe and deploy content, there is a gap in skills and resources that potentially prevents full use of quality metadata. [Currier 2004] explorers the lack of quality metadata in e-learning systems and suggests the need to improve quality assurance. This can be attributed, in part, to the need for metadata authors to have expert domain knowledge both about the assertions they are making and in the languages which are used to describe these assertions in order to successfully describe the properties of content in metadata.
In the specific case of accessibility, to make assertions about content, knowledge of the standards involved used for content accessibility, evaluation reporting, and user issues as a whole should be possessed by the asserter. The Web Content Accessibility Guidelines (WCAG) [Chisholm et al. 1999] and Evaluation and Report Language (EARL) [Chisholm and Palmer 2002] provide guidelines with which one could assert accessibility statements and the method to express such assertions. These need to be coupled to a set of profiles such as those produced by IMS in the Learner Information Package (LIP) [Beidler et al. 2001] with the accessibility information in accessibility for LIP (AccLIP) [Barstow et al. 2003].
There are tools that can aid the production of metadata that fulfills these needs. By using tools there is a risk, however, of losing quality in metadata because of the reduced domain knowledge of the majority of the newly empowered authors. This however, increases the overall coverage of the metadata, which raise the question of quantity versus quality. The general consensus is that some reduction in quality is acceptable when coverage is increased. However the dramatic reduction in quality which can occur emphases the need for quality assurance procedures.
[HERA] is a tool that allows users to step through a series of tasks with a minimum of prerequisite knowledge of WCAG [Chisholm et al. 1999] and make assertions about a resource according to the guidelines in WCAG using the schema in EARL [Chisholm and Palmer 2002]. As such there is the potential for a significant de-skilling in the process of creating metadata which describes the accessibility properties of a resource.
In order to provide quality assurance on the engineering of metadata, some notion of quality must first be applied, measured and controlled. Since the problem space may have already employed the de-skilling of metadata creation, there is little hope for expert appraisal in any measure. However, the system may provide a large number of users who make use of both the content itself and the metadata. As they are provided with content based on their profiles users, will inherently make ratings on the content and the metadata related to it. By giving users a formal method to record their ratings, we can view such a system as having a feedback method to ensure that metadata is being authored to an acceptable standard and areas of failure are being identified.
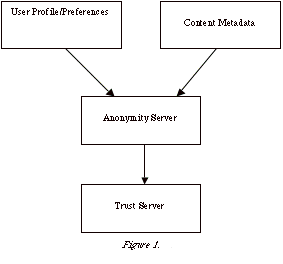
The proposed 'Trust' infrastructure consists of four major components:
With the anonymity server working as a central hub they form the basis of a system for ranking resources according to a given user profile.
When a user with a particular profile and set of preferences wishes to rank some content they ask the anonymity server to handle the request on their behalf. The anonymity server then checks the user's identity against the trust server to ensure it is appropriate for that user to make an assertion with their current profile and preferences. If so, the anonymity server then looks for any metadata relating to the content and the user profile/preferences and creates a ranking connected to the content metadata in addition to the content itself. In this way, the user performs a peer review of both the appropriateness of the content and the metadata associated with that content relating to their needs.
This generalised system demonstrates the interactions between the components. However, it requires that there be a mechanism in place that can authorise someone to use a particular profile or set of preferences. Such systems are likely to be specific to each e-learning environment and, as such, reduce the possibilities of interoperability. By using mechanisms already in place that are open and implementable, interoperability of systems can be maintained. Pretty Good Privacy (PGP) [Zimmermann 1992] is such a system. Using digital signatures is a common method for verification of identity; these use public/private key encryption and authentication systems. PGP is one of the most common systems that offers a range of features allowing signatures and encryption to take place within an integrated framework.
One implementation of a digital signature framework most people are familiar with is the TLS/SSL [Dierks and Allen 1999] encryption used on the World Wide Web. When shopping online, security is necessary when transmitting details such as credit card numbers, names and addresses. This system works by having so-called 'certificate authorities' who sign the encryption keys used by individual servers to verify that they are authentic and do not belong to a third party. This paradigm can be adopted in the case of user profiles. When user profiles are created in an assessment they can be signed by a trusted individual using a known key. This individual is acts analogously to a certificate authority and provides verification that the user has the right to use a certain profile.
This system also hold great potential to be very extensible. By keeping a list of trusted individuals who can verify users, it is trivial to provide users with certified profiles. Third parties can easily add new trusted certificates and hence include all the users that have been certified by them. Furthermore, if a certifier turns out to be untrustworthy it is technically trivial to revoke trust in them and hence their users.
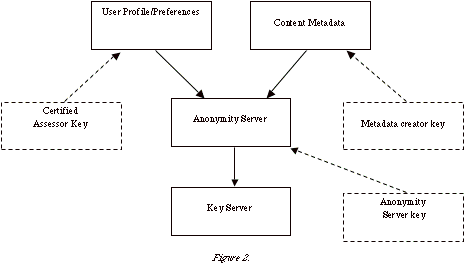
Figure 2shows the introduction of three new components and the redefinition of one component from Figure 1. By introducing keys for profile assessors and metadata creators the anonymity server can track and verify users and metadata in a completely placeless manner. The use of a key server to provide verification of keys provides a specific implementation of a trust server. In Figure 2 the key server must be trusted absolutely. A key has also been added referring to the anonymity server. This key allows users to encrypt traffic to the server, ensuring that potential communications attacks on anonymity are reduced. It also ensures that information can be published and updated to locations separate to the anonymity server while still maintaining joint secrecy with encryption. [Dumbill 2004] provides a methodology for signing and encrypting FOAF files with PGP.
FOAF [Brickley and Miller 2004] deals with personal information and the relationships that connect people together. It is ideal for the application being discussed as it adds a form of encapsulation with which a system can associate a diverse variety of properties with an individual. The associative features of FOAF also make it ideal to handle the types of relationships between users and content and authors and content, and to deal with the various assertions made about content.
Based on FOAF Golbeck, Parsia and Hendler created a social trust model in [Golbeck et al. 2003]. While that paper deals with implied trust by node traversal, that method is not required in this system. What is more relevant are the mechanisms used to integrate with FOAF and their implementation of an anonymity server. The authors recommend a simple binding that attributes a ranking to a person denoting social trust. From [Golbeck et al. 2003] the code example below shows a person, Joe, who has a unique identifier of his e-mail address. He trusts highly a resource, in this case a person, Sue.
<Person rdf:ID="Joe">
<mbox rdf:resource="mailto:bob@example.com"/>
<trustsHighly rdf:resource="#Sue"/>
</Person>
This example, and indeed [Golbeck et al. 2003]'s whole schema, deals with social trust of people. This is not appropriate for the ranking of resources in an e-learning system. Users are not making declarations of social trust in this context, instead a rating of their experience of interacting with a resource. This includes their ease of use, and hence the accessibility for someone with the same, or possibly similar, profile. As such it seems appropriate to create a new schema to reflect this.
Such an extension would allow different types of trust to be assigned to a resource allowing more appropriate types of inferencing. [Golbeck and Hendler 2004], for example, looks at a system of rating social trust networks that is not appropriate to other types of trust.
Trust.mindswap.org is a University of Maryland site on which Golbeck et al. have provided an implementation of a FOAF trust server. This server implements many features which are appropriate to a ratings system for e-learning. The main accommodation to the model from Figure 1 is the provision of an anonymous rating network. The trust.mindswap.org server takes input from a number of users about the people that they assign trust to. It can then calculate on demand the trust between users without directly revealing any of the nodes traversed to attain that trust.
Since the schema from [Golbeck et al. 2003] is not extensible beyond social trust networks, it is necessary to define a new schema to deal with more general trust issues. Notions of trust can be categorised as a measure capability and reliability. Capability is the ability of the resource to fulfil the needs of the trustee, reliability the likelihood that the resource will perform it in the context that is required. Thus, a resource that is fully able to fulfil the needs of the trustee, with enough fidelity to ensure it will be done at the appropriate time, would be fully trusted.
In the context of this system, there is no notion of reliability. All resources being rated have been delivered and there are no assertions being made on the likelihood of new resources being delivered. As such, all trust ratings are only affected by the capability of the resource to fulfil the needs of the trustee, in this case the user.
Drawing from [Golbeck et al. 2003] a model of trust can be defined comprising of the following levels:
[Rector 2004] suggests the use of "value partitions" and "value sets". Since the various ratings are inconsolable, a resource cannot be both highly trsuted and highly distructed on the same topic. When producing an ontology for trust ratings the use of a mechanism, like the one in [Rector 2004], to stop conflicts is necessary. Once this partitioning is done these levels could be applied to resources in terms of capability and reliability. In the context of this system a reliability of 9 is assumed for all trust assertions. The other machinery used in [Golbeck et al. 2003] to define trust can also be used. An example of this new schema might look like:
<Person rdf:ID="Simon">
<mbox rdf:resource="mailto:simon@example.com"/>
<genTrusts:trusts genTrust:Capability="Highly" genTrust:Reliability="Absolute" rdf:resource="#Page"/>
</Person>
The person Simon, with mailbox simon@example.com, is making a trust assertion about a resource, #Page. He is giving it a capability rating of "highly" indicating that he highly trusts the capability of the resource. The reliability of the resource has been given as "absolute" as stated for this system. A more accurate example for the given system might be:
<Person rdf:ID="Simon">
<mbox rdf:resource="mailto:simon@example.com">
<genTrust:trustsRegarding genTrust:Capability="Highly"
genTrust:Reliability="Absolute">
<genTrust:trustsResource rdf:resource="#Page"
/>
<genTrust:trustsOnSubject rdf:resource="#MyProfile"
/>
</genTrust:trustsRegarding>
</Person>
Here Simon is applying trust to #Page on the subject of his learner profile, including it's accessibility information, with a capability rating of "Highly". This method allows a description of Simon's perception of how well #Page fulfills the needs of his profile, #MyProfile.
Examining user rankings of content allows for a number of inferences to be made. Assertions about the content, the content metadata, the creators of the content and the content metadata, and the profile of the user can all be made from these inferences.
The user will make assertions directly about content. This means that there is a direct source of information available relating to a user of a particular profile giving a piece of content a rating to a certain level. In the simplest case, users assert that content is more or less appropriate for themselves. However since the users are profiled, this assertion could also apply to people with the same profile as the user that made the assertion. This might also be partially true for users with similar profiles. However, since profiles tend to be multidimensional, small changes can cause large disparities.
All content of course has an author (or authors), and as such any assertions about the content also reflect on the author. Ratings can be composited by author to look for areas of breakdown. This would allow authors' areas of weakness to be identified and addressed.
While the ratings relate to the content and the only direct assertions are restricted to content, it is possible to make inferences based on the content metadata. Since the content metadata is also making assertions about the content the two statements should be equivalent in areas of overlap (not all metadata may cover all areas of a user's profile). If they are not equivalent, then it follows that one or the other is to some degree incorrect. This does imply that if they are equivalent they are both correct, since they may both be equally wrong. While a single rating performed by an individual user is unlikely to be more authorative than an expert assessment collection of such ratings could be considered an indication of the correctness (or indeed incorrectness) of such an assessment.
If a metadata author is consistently making assertions which do not match those provided by user ratings then one could look at the areas in which there is disparity. In such areas the author can receive expert training to improve the quality of metadata they produce.
Just as the rating system reflects on authors of metadata if they produce assertions which do not match those of the users rating the content, it also reflects on a user if their ratings wildly vary from users with similar profiles. If a user makes a series of anomalous ratings it suggests two possibilities, either their profile is incorrect or they are creating deliberately misleading rankings.
If the user has indeed had a spurious user profile which has caused them to mis-rate resources then this creates further inferences about their original assessor. While it does not follow that a misdiagnosis of a user's need makes an assessor unreliable it does suggest investigation might be warranted.
While many inferences may produce useful information, this partly depend on some assumptions made about the system. The system can cope with a creator of metadata producing spurious assertions by using users to asses the validity of the metadata and highlight issues. The system can also cope with users (en masse or as individuals) making spurious assertions. It can, however, not cope with both creators of metadata and users producing false input.
There is also a weight in favour of user assertions which puts the onus on the metadata to show it is correct rather than the other way around. As such, assertions on metadata should not be automatic, but rather used as guidelines in the quality assurance process for the production and maintenance of metadata.
The types of inferences suggested here are just a selection of the possible inferences that could be made on any assertion in a given system. The section on further research examines possible areas of expansion.
With the dramatic increase in use of e-learning systems that facilitate QA of metadata will become invaluable. The proposed system offers an extensible solution to potential trust issues. However, the model of trust defined here is as yet untested and warrants further investigation.
It is hoped this paper has also shown, in some small way, the potential power of using a simple user metrics to produce powerful inferences using other information in the system. By taking highly focused input from the user surrounded by a precise and validated set of information the number of inference that could potential be made are far greater than those from either more complex user input, or more generalised systems in many cases.
There is also a set of existing technologies in FOAF, EARL, AccLIP and PGP that could be used to describe the accessibility of e-learning content regardless of ratings implied or made by users. FOAF seems an ideal choice for the packaging of user information when combined with encryption in the form of PGP to fulfil security requirements.
While the proposed system raises some interesting ideas, is still yet incomplete. Further is needed to be done to establish the detailed infrastructure under which the system will successfully run. For example, how many users need to rate content to give accurate inferences on the success of metadata? While statistical sampling methods can suggest possibilities, only real-world testing can authoritively establish these baselines.
The current system also uses a central key server. It would be useful to explore ways in which users can make their own assertions about content without a central authority or a compromise in their privacy and anonimity. This is especially relevent with the recent advances in distributed e-learning systems.
In a complex system many possible inferences arise from a given assertion. With a practical implementation of the proposed system it would be possible to look at correlations between user ratings and other systems features. This would provide evidence to support the inferences suggested in this paper and expose other possible inferences.
[Barstow et al. 2003]
Cathleen Barstow, Anastasia Cheetham, Martyn Cooper, Eric
Hansen, Andy Heath, Phill Jenkins, Hazel Kennedy, Liddy Nevile, Mark Norton,
Madeleine Rothberg, Joseph Scheuhammer, Brendon Towle, Jutta Treviranus, David
Weinkauf
IMS Learner Information Package Accessibility for LIP, Version
1 Final Specification
http://www.imsglobal.org/accessibility/index.cfm
[Beidler et al. 2001]
Susan Beidler, Geoff Collier, Andy Heath, Wayne Martin, Bill
Olivier, Tom Probert, Rob by Robson, Colin Smythe, Frank Tansey, Tom Wason
IMS Learner Information Packaging, Final Specification,
Version 1.0
http://www.imsglobal.org/profiles/index.cfm
[Brickley and Miller 2004]
Dan Brickley, Libby Miller
FOAF Vocabulary Specification 0.1
http://xmlns.com/foaf/0.1/
[Chisholm and Palmer 2002]
Wendy Chisholm, Sean B. Palmer
Evaluation and Report Language (EARL) 1.0
http://www.w3.org/TR/EARL10/
[Chisholm et al. 1999]
Wendy Chisholm, Gregg Vanderheiden, Ian Jacobs
Web Content Accessibility Guidelines 1.0
http://www.w3.org/TR/WCAG/
[Currier 2004]
Sarah Currier,
Metadata Quality in e-Learning: Garbage In - Garbage Out?
http://www.cetis.ac.uk/content2/20040402013222
[Dierks and Allen 1999]
T. Dierks, C. Allen
Request for Comments: 2246, The TLS Protocol Version 1.0
http://www.ietf.org/rfc/rfc2246.txt
[Dumbill 2004]
Edd Dumbill
Usefulinc FOAF information
http://usefulinc.com/foaf/
[Golbeck and Hendler 2004]
Golbeck, Jennifer, James Hendler
Accuracy of Metrics for Inferring Trust and Reputation in
Semantic Web-based Social Networks - Proceedings of EKAW 04.
http://www.mindswap.org/papers/GolbeckEKAW04.pdf
[Golbeck et al. 2003]
Jennifer Golbeck, Bijan Parsia, James Hendler
Trust Networks on the Semantic Web, Proceedings of
Cooperative Intelligent Agents 2003, Helsinki, Finland.
http://www.mindswap.org/papers/CIA03.pdf
[Rector 2004]
Alan Rector,
Representing Specified Values in OWL: "value partitions" and "value sets"
W3C Working Draft
http://www.w3.org/TR/2004/WD-swbp-specified-values-20040803/
[HERA]
Sidar Foundation,
HERA: Cascading Style Sheets for Accessibility Review
http://www.sidar.org/hera/
[Zimmermann 1992]
P. Zimmermann, PGP User's Guide, Dec. 1992.