|
Abstract
Bootstrapping is a problem that affects all applications of the Semantic Web, including the network of interlinked Friend-of-a-Friend (FOAF) profiles known as the FOAF-web. In this paper we introduce a hybrid system that not only gathers existing FOAF pro
files from the Semantic Web, but also applies known web-mining techniques to extract social network information from the original, hypertext web. To motivate our approach, we demonstrate how even the simple information obtained this way can be used effect
ively to obtain important insights into a community by applying the methods of Social Network Analysis, a branch of sociology concerned with relational data.
1. Introduction
The past year has seen the emergence of social networking sites as some of the most popular places on the web, with the first-mover Friendster attracting over 5 million registered users in the span of a few month. T
hese sites allow users to post a profile with basic information, to invite their friends and to link to their profiles in the system. The system also lets the users visualize and browse the resulting network in order to discover friends in common, friends
thought to be lost or potential new friendships based on shared interests.
Despite the early popularity, users have soon discovered a number of drawbacks to such centralized systems. First, the profiles stored in these systems cannot be exported in machine processable formats, which means that the information is not portable amo
ng social networking systems and needs to be maintained separately at all sites. Second, centralized systems did not allow users to control the information they provide on their own terms. Although Friendster follow-ups offer several levels of control (e.
g. public information vs. only for friends), users often still find out the hard way that their information was used in ways they did not foresee.
Both of these problems can be addressed with the use of Semantic Web technology. The Friend-Of-A-Friend (FOAF) ontology is a first attempt at a formal, machine processable representation of user profiles and friendship networks [1]. Unlike with Friendster
and similar sites, FOAF profiles are created and controlled by the individual user and stored and made public in a distributed fashion (typically posted on the personal web page of the user). Much like web pages, these profiles also link to the profiles
of friends, creating the so-called FOAF-web. In effect, the FOAF-web is a single social network described in a universal format that is directly amenable to machine processing.
Unfortunately, the FOAF-web is affected by the well-known bootstrapping problem of the Semantic Web: barring a flashy central portal or a single killer app, a critical mass of both metadata and applications are necessary to make the Semantic Web convincin
g enough for others to join. The problem of bootstrapping is thus that of the chicken and the egg: the value of the Semantic Web proposition depends on how much the Semantic Web is used on the first place. Besides a lack of motivation, the situation is ag
grevated by the fact that using Semantic Web technology represents a challenge for everyday web engineers, not to mention users of the web.
The only solution to the problem seems to be to 'lower the cost of laying an egg' (quote by Ian Horrocks, Victoria University of Manchester) by hiding the ugly face of technology (e.g. by creating user-friendly interfaces such as the FOAF-a-matic), minimizing the effort required by the users (e.g. by embedding the creation of metadata into their everyday activities) and reusing existing sources of information.
In this paper we capitalize on the last possibility by considering the traditional web as a source of information about the social networks in a community. We introduce a system for collecting social network data, which acquires data from the traditional
web by mining the index of Google, while it also crawls the Semantic Web in search of FOAF profiles. Necessarily, the quality of information obtained by web mining is expected to be inferior to that of manually authored FOAF profiles. Nevertheless, as we
will demonstrate on the example of a specific community with a significant online presence, the data obtained shows cognitive validity and proves to be rich enough in order to gain valuable insight into the social structure of the community.
In the following, we first introduce the architecture of the system in Section 2. We then turn to the specific setting of our case study involving the Semantic Web research community in Section 3, where we also reflect on some of the concerns and advantag
es of using our a system for the purposes of network analysis. We provide an analysis of the data collected in Section 3, both to demonstrate the power of SNA toolkit and to validate our approach. Lastly, we summarize the related work and draw our conclus
ions in Section 3.
2. System architecture
The system developed for collecting and analyzing online social networks is one of very few hybrid applications that combine methods of mining the traditional, human-oriented web with a crawling of the Semantic Web. (See Figure below for an overview of th
e architecture of the system.)
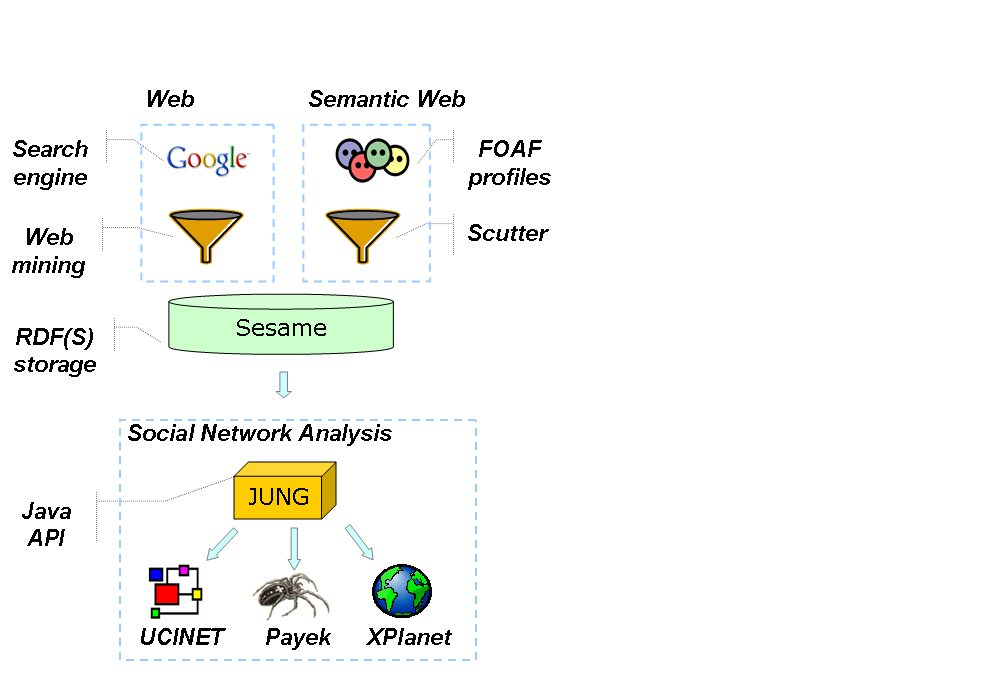
Given a set of names as input, one component of the system uses the search engine Google to obtain relational network data. This component works by submitting all possible pairs of names to the search engine and counti
ng the number of pages returned, i.e. the pages where the two names co-occur. Tie strength is then calculated by normalizing this result with the number of pages returned for the names queried individually. (This is also known as the Jaccard coefficient [
11].) The resulting value of tie strength is a zero or positive real number.
Given a set of names and a list of interests (or any other kind of domain concept), a related component performs a calculation of Google Mindshare to determine whether a given person is associated with a ce
rtain interest or not. The Google Mindshare of a person with respect to an interest is simply the number of the pages where the names of the person and the interest co-occur divided by the total number of pages about the interest. The strength of this ass
ociation is normalized only with the page count of the person involved, since association strength do not need to be compared across interests. The resulting measure is again a zero or positive real term, but in this case we fix the threshold for inclusio
n at one standard deviation from the mean of the values. (This is considered a 'rule of thumb' in SNA practice.)
The network ties and the interest associations are represented in RDF using the foaf:knows and foaf:topic_interest properties. Extensions of the FOAF model are necessary for the present system to record the provenance and timestamp of the da
ta collected as well as the weight of the relationships, when available. The RDF data is stored in Sesame, an RDF storage and query facility. Note that since the model is a compatible extension of FOAF, the 'ontologize
d' network data can be read as a set of FOAF profiles and processed by any FOAF-compatible tool.
Using the Semantic Web, social network data in the form of FOAF profiles is collected by crawling. The system uses a so-called scutter, a robot that traverses the RDF-web by following rdfs:seeAlso links. After recording the provenance and attaching
a time-stamp, the knowledge found is added to the Sesame store as well. (At present the only aggregation of FOAF data is based on N-Gram string matching on person names.)
In a next step, the data in the Sesame server is further enriched by adding the geographical locations of place names found in the FOAF profiles. This step is also carried out automatically by interacting with the Place Finder Sample Web Service that provides geo-location services for over three-million place names worldwide.
The data is further processed by the JUNG programming toolkit for (social) network analysis. JUNG is a Java library that provides an object-oriented representation of networks. JUNG also contains the algorithms
for calculating several basic network measures and makes it possible to build complex applications using the provided visualizations. (We will show an example of such an application in Section 4.3).
Advanced visualizations are crucial for theory-building in network analysis. For this reason and for performing more sophisticated analysis, the network data can also be exported from JUNG in the formats used by the Pajek and UCINET packages for Social Network Analysis. (Both tools offer further export to formats used by 3D visualizations.) The JUNG representation is also the basis for generat
ing marker and arc files for XPlanet. XPlanet visualizes geographic coordinates and geodesics by mapping them onto surface images of the Earth. (For reasons of brevity, the analysis of these images has been om
itted from the present paper.)
3. Experiment design
With the system introduced above, we collected data about the network of Semantic Web researchers during March, 2004. For our purposes, we defined the network boundary as including only those researchers whose names have appeared at least once as either p
rogram committee members or organizers of any of the three international Semantic Web events organized so far (N=167). (This includes the Semantic Web Working Symposium (SWWS) of 2001 and the First and Second International Semantic Web Conferences (ISWC)
held in 2002 and 2003.) This means that our focus is only on high-profile researchers, who are likely to be the most committed to this area of research. Unfortunately only a small fragment of this community has a published FOAF profile, which means that w
e had to rely on traditional web data for the current experiment.
Here, we would like to make a number of observations before treating web data as an input for social network analysis.
First, using the traditional questionnaire and interview methods of SNA, the notion of tie strength is treated as an aggregate measure reflecting the multiplexity of social relationships.
(However, there is no general agreement over what the underlying components and relationships are and how to operationalize their measurement in a reliable (domain-independent) way.)
In fact, the simple co-occurrence relationship of this network may reflect different types of relationships, such as co-authorship, co-participation at events etc. A closer look at the results for a single person (Frank van Harmelen) shows that 44 of the
first 100 results returned (from a total of about ten thousand) relate to publications. Although this hypothesis has not been tested, this suggests that the network may show a correlation to the co-authorship network of the researchers, taking multiplicit
y into account. (Popular publications are mentioned more often.)
Secondly, the data is bound to contain errors due to the method of collection. The search for co-occurrence is carried out on the syntactic level and shows the typical drawbacks of internet search. For example, it is possible that some of the returned pag
es are about a different person than the one intended by the query. Ambiguity particularly effects people with common names, e.g. Martin Frank. Furthermore, queries for researchers who use different variations of their name (e.g. Jim Hendler vs. James Hen
dler) or whose names contain international characters(e.g. Jérôme Euzenat) may return only a partial set of all relevant documents known to the search engine. (Note that the ambiguity of web searches with respect to the content is precisely t
he problem addressed by Semantic Web technology!) Further, a co-occurence of names on a web page need not indicate any social relation in the sociological sense and may be in fact a pure coincidence.
A related problem concerns the reliability of Google's results: the phenomenon of Google Dance can alter the measured value for the individual ties depending on the time of the query. Google updates the index of the webpages roughly once in a month. Durin
g the process of updating (which may take several days), the results obtained from Google may shift depending on whether the old or the new index is used to resolve a query. Since Google uses the DNS system for load balancing among data servers, it is pos
sible that a first query is resolved by a server with the new index, while a second query is served by a server which still holds the old index or vice versa. This phenomenon is called the Google Dance. Since the company does not publish information on th
eir exact procedures, the time of Google Dance can only be tracked by observing Google itself.
Lastly, concerns can be raised about the sensitivity of our analysis to the definition of the network boundary, i.e. the initial choice of researchers. While this is a well-known problem in SNA, we have experimented with the sensitivity of some of the mea
sures with respect to the size of the network. For example, when removing nodes from the network (and thus simulating the effect of missing information), we have found that the value of closeness centrality (see following section) remained highly correlat
ed to its original value even when removing a significant number of nodes. For example, on a network of 39 nodes correlation still reached 0.8 after removing a third of all nodes. This gives us sufficient confidence in the reliability of our results.
4. Analysis
In this section we present some of the analysis we have carried out in terms of global network measures (Section 4.1), ego-network measures (Section 4.2) and subgroup analysis (Section 4.3). All the techniques used in this Section are part of the standard
toolkit of Social Network Analysis and described in a number of textbooks (e.g. [4,5]).
4.1. Global network measures
As discussed before, the system we have developed provided a continuous value for the tie strengths between the researchers. By looking at this distribution, we have found that it follows a power-law (R^2=0.9848), with a mean of 10 and a standard deviatio
n of 15.3. We have decided to analyze two networks by choosing two different thresholds for tie strength.
After deleting the ties below the first threshold of 30 and removing social isolates, the network contained 124 nodes and six components, with a large component of size 114 and five pairs of individuals. (A component is a maximally connected subgraph [4].
) In the following, we will refer to this component as the entire network.
Following the same procedure with a higher threshold of 50, the network was left with 93 nodes and 15 components, with a large component of 37. As this component can be considered as the strong core of the entire network, we will refer to it in the follow
ing as the core of the network.
The network also exhibits a small-world structure [12]: a high degree of clustering with a small average separation. The entire network had a clustering coefficient of 0.15 and an average separation of 4 degrees. (The clustering coefficient is a measure o
f the density of the social network of an individual, i.e. the degree to which the ego's friends (relations) are also friends (relations) of each other. Separation refers to the length of the shortest path in the graph between two nodes.) The degree distr
ibution follows a power law (R^2=0.5673) in accordance with the Barabási model of small worlds [13,14] that also predicts the average separation to be on the order of log(N).
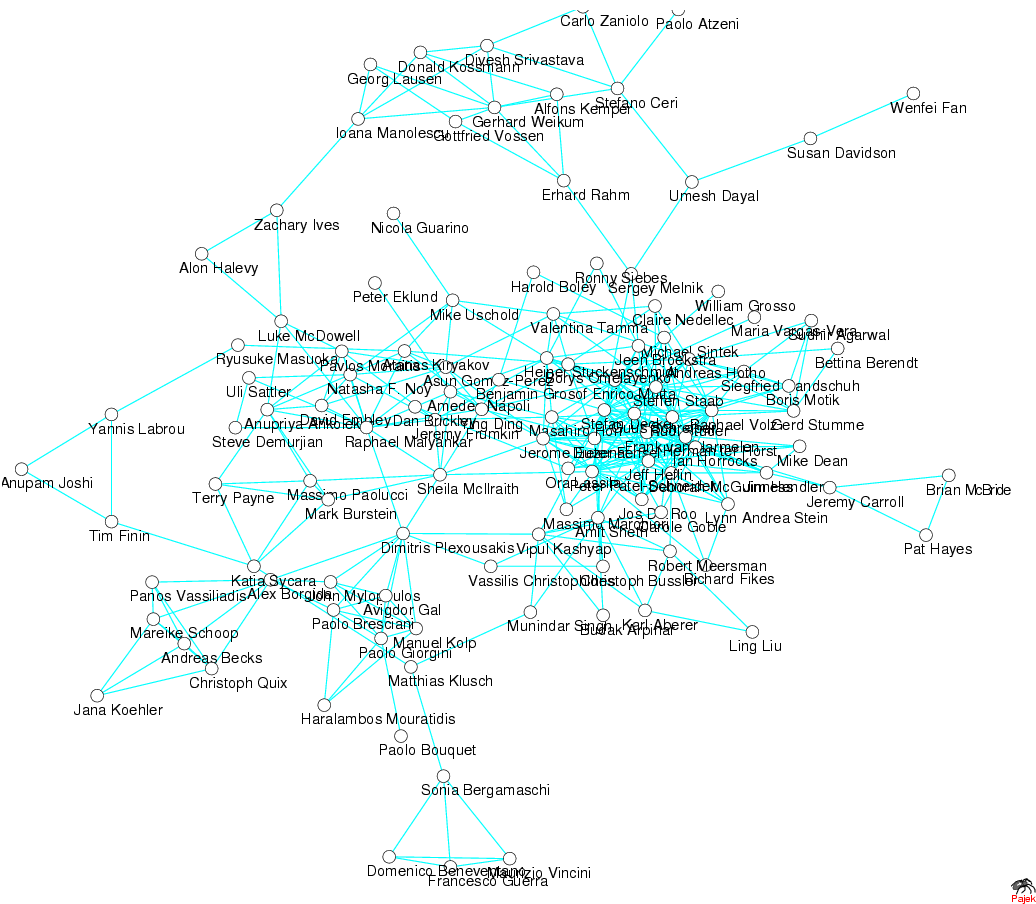
When laid out graphically, the image of the network suggests an underlying core-periphery structure to the network (see Figure below). Nodes with the highest centrality make up a single connected cluster in the graph. This combined with our subgroup analy
sis implies that there is a dense core (with possible several concentric circles of influence) surrounded by a number of smaller sub-communities connected more loosely to this core (see also Section 4.3). We hope that after we will be able to observe this
network over time we can determine conclusively the existence of a Semantic Web elite and the options for social mobility.
4.2. Ego-centered network measures
A key idea in the structural approach to social science is that the way an actor is embedded in a network offers opportunities and imposes constraints on the actor. Occupying a favored position means that the actor will have better access to information,
resources, social support etc. and will be exceedingly thought after for such opportunities by actors in less favorable positions.
In particular, power and influence in informal networks stem from occupying positions that are central to the network. The measure of centrality has been the subject of several studies in SNA and a number of operationalizations have been proposed.
A simple, but effective measure is the degree centrality of the node [4,5]. Degree centrality equals the graph theoretic measure of degree, i.e. the number of (incoming, outgoing or all) links of a node. This measure is based on the idea that an ac
tor with a large number of links has wider access to the network, less reliant on single partners and because of his many ties often participates in deals as a third-party or broker. Degree centrality does not take into account the wider context of the eg
o and nodes with a high degree may in fact be disconnected from large parts of the network. However, the degree measure features prominently in the scale-free model, which makes it an important measure to investigate (see above).
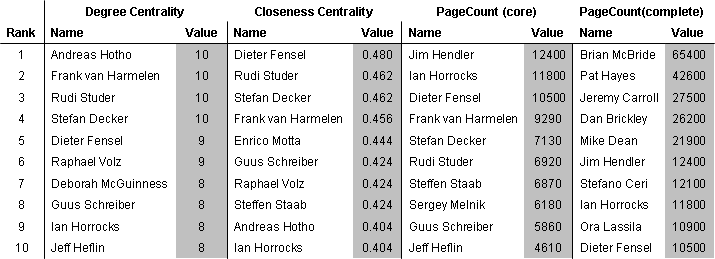
A second, more intuitive measure of centrality is closeness centrality, which is obtained by calculating the average (geodesic) distance of a node to all other nodes in the network. Closeness centrality thus characterizes the reach of the ego to al
l nodes of the network. The Figure above shows the ten highest ranking nodes of the network in terms of degree and closeness centrality. For comparison, we also included the highest ranking nodes by the measure of page count (the number of pages returned
by Google for an individual) for both the entire network of 167 nodes and the strong core of 37 nodes.
Two other measures of power and influence are related to the advantage gained through brokering. Betweenness centrality measures the extent to which other parties have to go through a given actor to conduct their dealings. Consequently, betweenness
is defined as the proportion of paths -among the geodesics between all pairs of nodes- that pass through a given actor.
The more complex measure of Ronald Burt is related to the idea of structural holes [15]. A structural hole occurs in the space that exists between closely clustered communities. According to Burt, a broker gains advantage by bridging such holes. (B
rokers are even claimed to have better ideas due to their extended vision [16].) Therefore this measure favors those nodes that connect a significant number of powerful, sparse linked actors with only minimal investment in tie strength. (Weak ties are pre
ferred over strong ties as strong ties require time and effort to establish.) The Figure below shows the ten highest ranking nodes of the network according to betweenness centrality and Burt's measure.
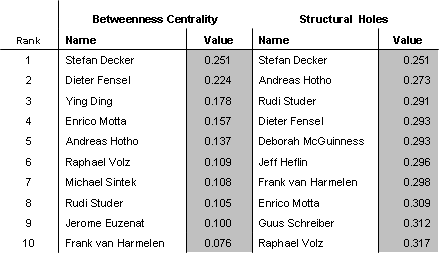
There are a number of observations to be made. First, the measures introduced above are distinct from the most common measure of popularity on the web, namely the page count. The sociological measures of closeness and degree centrality and Burt's Structur
al Holes are only weakly related to the page count, with a correlation of 0.66, 0.45 and 0.51 among the rankings of nodes in the core, respectively. The measure of betweenness is practically unrelated to pagecount, with a correlation of 0.26.
Large discrepancies can be found in both directions. Individuals who are popular on the web, but do not show closeness centrality include Harold Boley, Benjamin Grosof and Jim Hendler. (Taking the entire network into account, we can conclude that from the
list of top ten people with the most web pages only three are to be found in the core.) On the other hand, there are also individuals who appear on a relatively small number of pages considering their centrality to the Semantic Web research community (ex
amples include Borys Omelayenko, Andreas Hotho and Ying Ding).
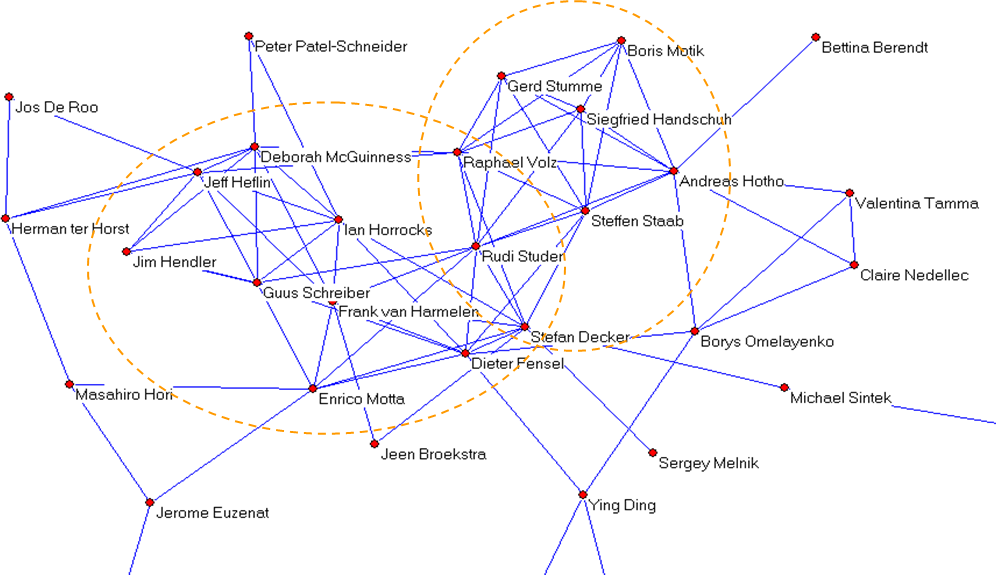
Degree, closeness centrality and Burt's measure are more highly inter-correlated than they are correlated with betweenness. Betweenness in our network favors those individuals at the outer perimeter of the core who connect the core with large clusters of
the periphery. A typical example is the case of Stefan Decker. Decker, having worked in Karlsruhe, have published with various past and present members of the AIFB and DFKI institutes as well as interacting with other key members of the Semantic Web comm
unity in highly active projects such as On-To-Knowledge and IBROW. This record puts him in a good position to connect the closely knit Karlsruhe-circle with the rest of the network. (See Figure above.) Burt's Structural Holes strikes a balance among betwe
enness and the measures of degree and closeness centrality, which clearly attribute more power to people in the very center of the core.
Second, there is cognitive evidence that the measures of degree and closeness centrality are successful in distinguishing the important members of the community. Ian Horrocks, Dieter Fensel, Frank van Harmelen have been the chairs of the three ISWC confe
rences held up to date (2002-2004). Stefan Decker and Deborah McGuinness were two of the four chairs of the Semantic Web Working Symposium (SWWS) held in 2001. Rudi Studer and Stefan Decker represent also two of the four editors' in chief of the recently
established Journal of Web Semantics. Deborah McGuinness, Frank van Harmelen, Jim Hendler and Jeff Heflin, Ian Horrocks and Guus Schreiber have been co-chairs and/or authors of key documents produced by the Web Ontology Working Group of the W3C, the most
influential standards organization in the Semantic Web area.
4.3. Subgroup analysis
As we know from the walks of everyday life, a large community often breaks up to a set of closely knit groups of individuals, woven together more loosely by the occasional interaction across groups. Based on this theory, SNA offers a number of clustering
algorithms for identifying communities based on network data. Alternatively, the subgroups may be identified by the researcher using additional attribute data on the subjects. We have tested both approaches in our work.
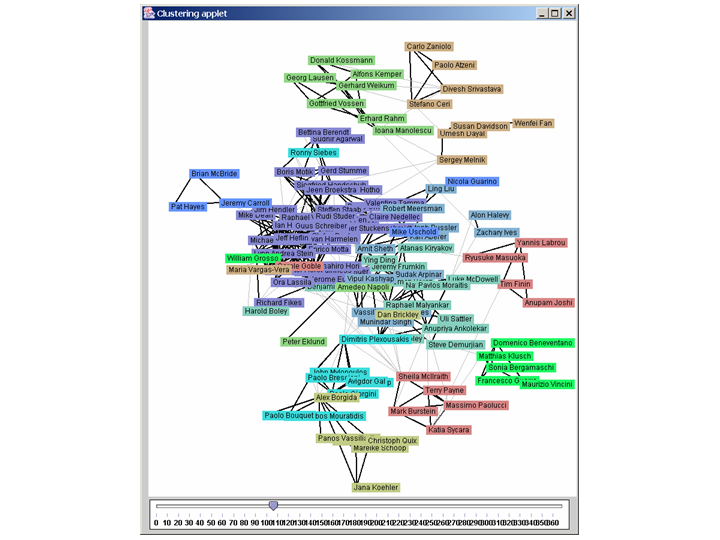
First, we have used an interactive clustering software provided as a sample with the JUNG Java toolkit for SNA. This software allows the user to cluster a network using an edge-betweenness clusterer and visualize the results. The user can "play" with the
algorithm by adjusting the threshold on a slider-bar. Stronger or weaker clusters appear based on this setting. This kind of interactive approach is necessary for performing clustering, since it requires the judgement of the researcher to determine the po
int where the algorithm gives the best results.
Again, the results have clear face validity. As an example, the previously mentioned group of researchers from the AIFB Institute of the University of Karlsruhe quickly emerges as a single cluster of the network. Interesting to note that this affiliation
based clustering is less apparent when it comes to groups from other universities, which may be a result of a higher propensity of the Karlsruhe group for co-authoring with their colleagues. Clusters based on topicality can also be observed.
Secondly, the success of our experiment gave us the idea of extending our work with mining research-topic interests as described in Section 2. As input, we have used a list of 24 key terms which characterize some of the common research directions within t
he Semantic Web community. We used the Payek tool to analyze the two-mode network that combined the original network with the research-interests of the individuals.

Once again, the results provided clear insight into the social structure of Semantic Web research. The DAML-S community, for example, is explicitly delineated in the network by our measure of association (see Figure above). These results highlight those r
elated to DAML-S either by being members of the DAML-S Coalition or as frequent contributors to the discussions (e.g. Ian Horrocks). With the availability of temporal data, we hope to follow over time the moveme
nt and development of this and other communities.
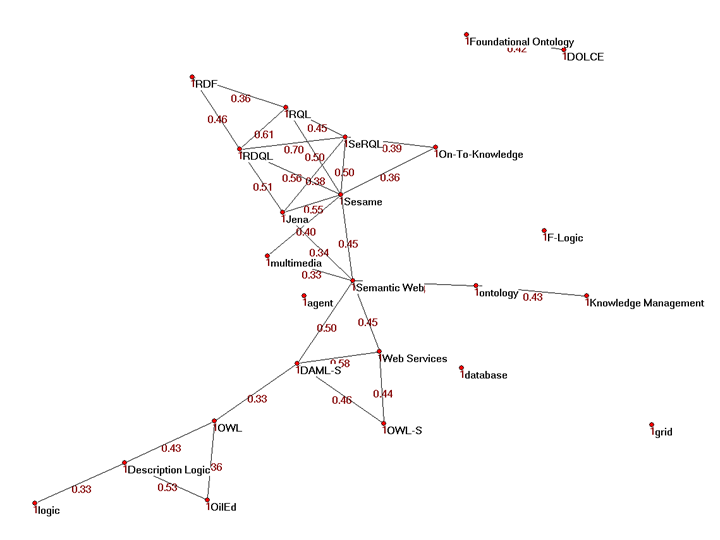
We have also translated the two-mode network of people and research topics into a regular network where the nodes represent the research topics and the values of the lines give the number of researchers in common to any two topics. (Again, we filtered out
the lines below a certain threshold.) The resulting diagram is familiar to those who know the work of this research community (see Figure above). For example, it is well known that OWL-S and DAML-S are languages for the description of Web Services. It is
also the case that OWL is based on Description Logic, OilEd is an OWL editor and Sesame is an RDF storage facility developed in the EU On-To-Knowledge project. Note also that the layout algorithm naturally places the notion of Semantic Web as the central
concept in this semantic network. In our current work, we are evaluating this method as way of learning the domain ontology of a community in comparison to traditional methods of mining associations. We argue that mining concept associations through the
associations of people and concepts represents an improvement over traditional methods of ontology mining using Google. The reason is that by querying for people and concepts together, we filter out those pages where the concepts are used in a different m
eaning. This is an improvement especially in case of terms that have a general sense as well as a community-specific interpretation.
Note that it is also possible to analyze the network of concept associations using the techniques introduced in this Section, for example to find the concepts that are most central to this community. For lack of space, however, we defer expounding this wo
rk to future publications.
5. Conclusion
The scope of related work is far and wide due to the interdisciplinary nature of our work, combining Web Intelligence and Social Network Analysis. With respect to our experiment, the closest precursor to be found in the literature is the Referral Web proj
ect, where data about the AI community was collected in a similar fashion by crawling the web and exploiting a search engine [17]. However, the data was used for a different purpose, namely interactive exploration of the network and the automation of refe
rrals. Traditionally scientific communities have also been studied by analyzing the linking structure of the Web (see for example the EICSTES project) or relying on publication or project databases [18,19]. With respe
ct to our method, Google has been used most recently by Cimiano et al. for the purposes of ontology learning. Their work also relies on the possibility of finding associations by observing the number of pages returned for a certain combination of terms [2
0].
With respect to our tool for data collection, we plan to deploy it in a longitudinal study of the Semantic Web community. Since our system is fully automated at the moment, it gives a so far unexplored opportunity in observing community dynamics over time
. (The effort required by the traditional questionnaire methods of network analysis rarely allow for repeated data collection.) We are planning to carry out our data collection throughout a minimal one year period and report in future publications on chan
ges and trends in the structure of the Semantic Web research community. We plan to use more Semantic Web data in the future (as it becomes available), but as we have shown even by relying on web data the results have immediate face validity to the researc
her who is informed about the workings of the community in question.
Needless to say, none of these earlier work could leverage the Semantic Web, which promises better precision and easier integration of all data sources. We also plan to validate our experiment by comparing the results to the outcomes of a survey that uses
the traditional questionnaire methods of network analysis. The validation of an online experiment with real world data is a unique attempt compared to the related work.
Acknowledgement Research for this paper has been generously funded by VUBIS, the VU Research School for Business Information Sciences.
6. References
1. Brickley, D., Miller, L.: FOAF Vocabulary Specification. Technical report, RDFWeb
FOAF Project (2003)
2. Gruber, T.R.: Towards Principles for the Design of Ontologies Used for Knowledge
Sharing. In Guarino, N., Poli, R., eds.: Formal Ontology in Conceptual Analysis
and Knowledge Representation, Deventer, The Netherlands, Kluwer Academic
Publishers (1993)
3. Golbeck, J., Hendler, J.: Inferring Reputation on the Semantic Web. In: Proceedings
of the Thirteenth International World Wide Web Conference (WWW2004),
ACM Press (2004)
4. Scott, J.P.: Social Network Analysis: A Handbook. 2nd edn. Sage Publications
(2000)
5. Wasserman, S., Faust, K., Iacobucci, D., Granovetter, M.: Social Network Analysis:
Methods and Applications. Cambridge University Press (1994)
6. Broekstra, J., Ehrig, M., Haase, P., van Harmelen, F., Kampman, A., Sabou, M.,
Siebes, R., Staab, S., Stuckenschmidt, H., Tempich, C.: A Metadata Model for
Semantics-Based Peer-to-Peer Systems. In: Proceedings of the 1st Workshop on
Semantics in Peer-to-Peer and Grid Computing. (2003)
7. Masolo, C., Vieu, L., Bottazzi, E., Catenacci, C., Ferrario, R., Gangemi, A., Guarino,
N.: Social Roles and their Descriptions. In: Proceedings of the Ninth International
Conference on the Principles of Knowledge Representation and Reasoning
(KR2004). (2004)
8. Gangemi, A., Mika, P.: Understanding the Semantic Web through Descriptions
and Situations. (In: Proceedings of the International Conference on Ontologies,
Databases and Applications of Semantics (ODBASE2003))
9. Adams, R.G., Allan, G., Oliker, S.J., Marks, S.R., Harrison, K., OConnor, P., Feld,
S., Carter, W.C., eds.: Placing Friendship in Context. Cambridge University Press
(1999)
10. Hite, J.M.: Patterns of multidimensionality in embedded network ties: A typology
of relational embeddedness in emerging entrepreneurial firms. Strategic Organization!
1 (2003) 11-52
11. Salton, G.: Automatic text processing. Addison-Wesley, Reading, MA (1989)
12. Watts, D.J.: Six Degrees: The Science of a Connected Age. W.W. Norton &
Company (2004)
13. Newman, M.: Models of the Small World: A Review. Journal of Statistical Physics
101 (2000) 819-841
14. Albert-László Barabási: Linked: The New Science of Networks. Perseus Publishing
(2002)
15. Burt, R.: Structural Holes: The Social Structure of Competition. Harvard University
Press (1995)
16. Burt, R.: Structural Holes and Good Ideas (in press). American Journal of Sociology
110 (2004)
17. Kautz, H., Selman, B., Shah, M.: The Hidden Web. AI Magazine 18 (1997) 27-36
18. Barabási, A., Jeong, H., Neda, Z., Ravasz, E., Schubert, A., Vicsek, T.: Evolution
of the social network of scientific collaborations. Physica A 311 (2002) 590-614
19. Grobelnik, M., Mladenic, D.: Approaching Analysis of EU IST Projects Database.
In: Proceedings of the International Conference on Information and Intelligent
Systems (IIS-2002). (2002)
20. Cimiano, Philipp and Handschuh, Siegfried and Staab, Steffen: Towards the Self-Annotating Web. In: Proceedings International WWW Conference (WWW2004), New York, USA. (2004)
|