
Ontology Driven Architectures and Potential Uses of the Semantic Web in
Systems and Software Engineering
Editors' Draft $Date: 2006/02/11 18:04:48 $
- This version:
- http://www.w3.org/2001/sw/BestPractices/SE/ODA/060211/
- Latest version:
- http://www.w3.org/2001/sw/BestPractices/SE/ODA/
- Previous version:
- http://www.w3.org/2001/sw/BestPractices/SE/ODA/060103/
- Editors:
- Phil Tetlow, IBM, <philip.tetlow@uk.ibm.com>
Jeff Z. Pan, University of Aberdeen, <jpan@csd.abdn.ac.uk> (Formerly University of Manchester)
Daniel Oberle, Universität Karlsruhe, <oberle@fzi.de>
Evan Wallace, National Institute of Standards and Technology, <ewallace@cme.nist.gov>
Michael Uschold, Boeing, <michael.f.uschold@boeing.com>
Elisa Kendall, Sandpiper Software, <ekendall@sandsoft.com>
- Additional Contributors and Special Thanks to:
- Andrea Zisman, City University London, <zisman@soi.city.ac.uk>
- Alan Rector, Manchester University, <rector@cs.man.ac.uk>
- Michael Goedicke, Universität Essen , <goedicke@s3.uni-essen.de>
- Grady Booch, IBM, <gbooch@us.ibm.com>
Copyright ©
2003 W3C® (MIT, ERCIM,
Keio), All Rights Reserved. W3C liability,
trademark
and document
use rules apply.
This note outlines the benefits of applying knowledge representation languages
common to the Semantic Web, such as RDF and OWL, in Systems and Software Engineering
practices.
This note is aimed at industrial professionals, tool vendors and academics
with an interest in applying Semantic Web technologies in Systems and Software
Engineering (SSE) contexts. These may include:
- Software Engineers who are interested in the benefits and potentials of
Semantic Web technologies
- Members of the Semantic Web community
- Members of the Model Driven Architecture (MDA) community who may be interested
in ontologies as models
- Members of the the automated software engineering community who are interested
in formal methods for [partially] automating the development of software systems
- Knowledge Representation and Inference researchers interested in practical
applications
- To enthuse SSE practitioners about the potential uses the Semantic Web and
Semantic Web technologies in SSE
- To outline the benefits of applying Semantic Web technologies in SSE contexts
- To encourage collaboration between the Semantic Web and Systems and Software
Engineering communities
Status of this document
This section describes the status of this document at the time of its
publication. Other documents may supersede this document. A list of current W3C
publications and the latest revision of this technical report can be found in
the W3C technical reports index at
http://www.w3.org/TR/.
This is a public (WORKING DRAFT) Working Group
Note produced by the W3C
Semantic Web Best Practices & Deployment Working Group, which is part of
the W3C Semantic Web activity.
Discussion of this document is invited on the public mailing list public-swbp-wg@w3.org (public archives).
Public comments should
include "comments: [SE]" at the start of the Subject
header.
Publication as a Working Group Note does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or obsoleted
by other documents at any time. It is inappropriate to cite this document as
other than work in progress. Other documents may supersede this document.
1. Introduction
Until recently work on accepted practices in Systems and Software Engineering
(SSE) has appeared somewhat disjointed from that breaking ground in the area of
formal information representation on the World Wide Web (commonly referred to as
the Semantic Web initiative). Yet obvious overlaps between both fields are
apparent and many now acknowledge merit in a hybrid approach to IT systems
development and deployment, combining Semantic Web technologies and techniques
with more established development formalisms and languages like the Unified
Modeling Language (UML). This is not only for the betterment of IT systems in
general, but also for the future good of the Web, as systems and Web Services
containing rich Semantic Web content start to come online.
This note attempts to outline how Semantic Web technologies can be applied in
Systems and Software Engineering, as well as the benefits such applications
could bring. Firstly, we will review the rise of ontology driven architecture
(ODA) in Section 2.
We then, in Section 3,
propose some ideas based on ODA and, more generally, on how Semantic Web
technologies can be applied in Systems and Software Engineering. Some of these
ideas are illustrated by the examples presented in Section 4.
Finally, Section
5 outlines possible next steps in the near future.
2. Background
2.1 History
Those who are familiar with the heritage of software development might
correctly suggest that the application of formal logic and declarative knowledge
representation in Systems and Software Engineering is not new, holding up much
good work in the areas of Automated Software Engineering, Formal Methods, Domain
Theory, Relational Algebra and real-time and embedded systems engineering.
Indeed, related approaches have seen much research for many decades now. The
following list therefore aims to provide a brief overview of established
academic work and industrial practice on which further discussions in this note
are based.
- Knowledge-based Software Engineering
A field of endeavour established nearly twenty years ago, with its annual
conference (the International Conference on Software Engineering and Knowledge
Engineering [SEKE
2005]) already in its 17th year. Relevant topics include AI approaches
to Software Engineering, automated reasoning and software design, knowledge
representation, retrieval, visualization and many more related topics.
- Goal-Driven Requirements Engineering
Since the early 1990s, research in this area has considered UML-based domain
models as parts of software architectures. [Pohl
1999]
- Faceted Software Classification
The work on faceted software classification also goes back to the late 1980s.
Its goal is to facilitate reuse of software components by attaching keywords
to them, then are organized these into facets. [Pietro-Diaz
1991]
Following on from such works, modelling a common understanding of domains
through formal and semi-formal methods has proven itself essential to advancing
the practice. Modelling as a discipline for architecting, developing,
communicating, and verifying abstract designs is now an integral best practice
in Software Engineering, as in other engineering communities. Computer Aided
Software Engineering (CASE), the Zachman framework for enterprise architecture,
and, more recently, Model Driven Architecture® (MDA®) are prominent examples of
this approach. We will highlight the latter in the subsequent section.
2.2 Model Driven Architecture (MDA)
In the Object Management Group (OMG)'s MDA initiative, models are used not
only for design and maintenance purposes, but as a basis for generating
executable artifacts for downstream use. The MDA approach grew out of much of
the standards work conducted in the 1990s in the Unified Modeling Language
(UML). It encourages model-based Software Engineering through
- specifying systems independently of the platforms that they will ultimately
be deployed on,
- specifying the platforms themselves and enabling generation of the software
artifacts specific to those platforms (e.g., J2EE, CORBA IDL, WSDL),
- supporting platform selection, and
- enabling transformation of system specifications into specifications for
particular deployment platforms.
Critical to the success of such an approach are firstly the notion of
separation of architectural concerns at every step in the design process, and
secondly well-designed models, models that can be used to orchestrate
understanding of a design in all phases of the development lifecycle. MDA
provides a methodology and the basic requirements for tools that prescribe the
kinds of models that may be used at each design phase, how they should be
developed to maximize reuse, portability, and interoperability, and the
relationships among them to support such code generation. It insulates
business applications from technology evolution through increased platform
independence, portability and cross-platform interoperability, encouraging
developers to focus their efforts on domain specificity.
The OMG's Meta Object Facility (MOF) standard defines the metadata
architecture that is central to MDA-based computing. MOF tools use
metamodels to generate code that manages metadata -- as XML documents, CORBA
objects, Java objects, WSDL services, and so forth. This generated code includes
access mechanisms, or application programming interfaces, to read and
manipulate, serialize and transform, and abstract the details of various
interfaces based on access patterns. From a knowledge representation
perspective, however, MDA only gets part of the job done. The suite of
standards supporting the MDA initiative streamline the mechanics of managing and
integrating models of various aspects of a system's design, but say little about
the underlying semantics of the domain being modeled.
Formal representation can help to limit ambiguity and improve quality not
only in automation of business semantics but in overall engineering of
complex systems. Yet, with
increasing formality, tool support can be increasingly abstract, which makes
methods more difficult to implement and may limit the freedom of expression
available to the engineer. On the other hand, less formal approaches can be
notoriously ambiguous: an isolated model, no matter how well specified, can be
open to misinterpretation by those who are not familiar with the problem space.
Supporting documentation can help alleviate such issues, but in practice,
outside of the MDA community, development of documentation is frequently
independent from actual model development. Further, MDA does not currently
support automated consistency checking or validation, although much has been
accomplished in related disciplines including Automated Software Engineering.
While MDA provides a powerful and proven framework for Systems and Software
Engineering, Semantic Web technologies can naturally extend it to enable
representation of unambiguous domain vocabularies, model consistency checking,
validation, and new capabilities that leverage increased expressivity in
constraint representation. Semantic models, or ontologies, will augment the OMG
standards and methodology stack, hence giving rise to Ontology Driven
Architecture (ODA).
2.3. Recent Developments
Over
the past two years there has been significant work to bring together Software
Engineering languages and methodologies such as the UML with Semantic Web
technologies such as RDF and OWL, exemplified by the OMG's Ontology Definition
Metamodel (ODM). While this work has been largely motivated by an interest to
exploit the popularity and features of UML tools for the creation of
vocabularies and ontologies, some have also advocated the potential benefits of
applying Semantic Web concepts to model validation and automation, as well as to
enable new Software Engineering capabilities.
The relatively recent introduction of Web Service concepts and technologies
also adds compelling reason for the drive to use web-friendly ontologies in
Systems and Software Engineering. Such concepts allow declarative functionality
to be deployed, discovered and reused over the web to obvious advantage. Given
the old computing adage that "all the software functionality needed in the world
has already been written somewhere," it theoretically follows that if all this
functionality were made openly available via Web Service interfaces, software
construction would become a radically different and simplified activity. That is
so long as Web Service metadata is accurate, complete and easy enough to use -
and that's where formal ontologies and Semantic Web languages come into play.
Indeed one could now consider that, given the vastness of the Web and the
communal culture it promotes, the future of software development may well not
actually lie in the construction of new functionality, but rather the discovery
and gluing together of existing functionality to achieve all the desired aims of
the solution in mind.
It may be fair to argue that the Semantic Web brings little that is new to
Software Engineering. Formal methods, rigorous domain definition and knowledge
based approaches have been explored with limited success outside the real-time,
embedded software community to date. So what is it about the amalgamation of
OWL, UML and the Model Driven Architecture (MDA) that will make a difference,
and why now? Given that the rate of increase in scalability, performance,
distribution, and interoperability requirements demonstrated over the last
decade remains relatively constant, the mandate for new capabilities that
further abstract and automate Software Engineering processes is clear.
Even small-scale, incremental improvements in low level capabilities have
historically led to enormous gains at higher levels. Advances internal to
the Systems and Software Engineering community have not been sufficient to tip
the scales thus far, but multidisciplinary approaches, such as bridging Semantic
Web and MDA technologies in novel ways, may enable such significant
improvements.
As simple as it may sound, the Semantic Web brings one huge advantage - the
Web itself - which has previously proved critical to the acceptance of at least
one, somewhat less than original, idea in IT. Java has gained widespread
adoption in global software development in recent years, yet its main features
are far from different to those of dozens of earlier programming languages. What
is unique, however, is that it is specifically targeted at Web-based systems and
is standards-based - both properties also common to the Semantic Web. For
this reason alone it is compelling to think that a combination of OWL, UML and
MDA might indeed make a real difference.
Additionally, as mentioned above, MDA mandates separation of concerns at many
levels; some MDA proponents advocate not only abstracting implementation
characteristics from business logic but taking significant care in defining the
agreements that software components expose via their interfaces. A critical
component of this practice is to carefully represent the preconditions,
post-conditions, and what are called invariant rules (similar to necessary and
sufficient conditions in description logics), to specify the behaviors of these
components under various circumstances. The aim here is to make such rules
unambiguous, enabling increasing automation based on the models, composition of
components, and limiting misunderstanding of the design. Primary
limitations to widespread adoption of this practice, known as
Design-By-Contract, include scalability as the number of rules increases,
particularly in large-scale, complex designs, the ability to do more than
cursory consistency checking, and unambiguous separation of the domain
terminology from the rules themselves. Semantic Web technologies can
dramatically improve this discipline by (1) enabling unambiguous representation
of domain terminology, distinct from the rules, (2) enabling automated
consistency checking and validation of invariant rules, preconditions, and
post-conditions, and (3) supporting knowledge-based terminology mediation and
transformation for increased scalability and composition of components.
While collaboration between the Semantic Web Services and MDA communities is
just beginning to occur, we see this as a tremendous opportunity for significant
productivity and software quality improvement.
Regardless of the benefits that Semantic Web technologies can bring to
Systems and Software Engineering, it is still worth noting that metadata
ontologies can be difficult to construct, maintain and use. As such a number of
tools have been produced to facilitate the engineering and maintenance of RDF
and OWL ontologies. These range from text-based editors/validators through to
experimental graphical environments. Further tools have also been created to
enable inferencing over such ontologies. References to relevant tooling can be
found at sites like semanticweb.org.
Related research is listed in Appendix.
3. Proposed Ideas
3.1 The Semantic Web in Systems and Software
Engineering
Having raised the idea of using of the Semantic Web in Software Engineering,
a commonly asked question arises; namely, how does one broadly characterise the
Semantic Web in terms of Systems or Software Engineering use? In attempting to
answer this question, two loose definitions are apparent:
- As a 'classification', merely to group together related
tools and techniques for modeling rigorous semantics during specification and
design stages of the Software Lifecycle.
Primarily such tools and techniques should be viewed as being formally
descriptive in character, but there appears little reason to restrict this
definition other than standards alignment. Therefore, it may also be relevant,
at some appropriate point in the Semantic Web's future, to include
prescriptive, invasive and/or other types of approaches under this
heading.
- As a 'mechanism' for rigorously describing, identifying,
discovering and sharing artifacts amongst discrete subsystems, systems and
systems' design teams both during design and at runtime.
In such circumstances the Semantic Web can be viewed as a set of formalised
corpora of interrelated, reusable contents, which can further be classified as
being either:
- Passive (data in the form of):
- Flat documents and data (HTML, XML etc).
- Dynamically generated documents and data (via JSP, PHP etc).
- Metadata (RDF, OWL etc).
- Media - pictures video, music etc.
- Databases.
- Active (functionality presented as):
- Web Services (inc Semantic Web Services).
- Functional components referenced as fragments within passive content
(JavaScript, Java applets etc).
The presence of both of these types is highly important, as is the fact
that they can be indistinctly described using ontological techniques and
technologies. Yet their distinction is paramount in the Systems and Software
Engineering space. On their own they are of limited from an automated systems
engineering standpoint (requiring intelligent agents like humans to cater for
the missing type), but combine then together using technologies that can treat
them equally and all the ingredients needed to automatically compose fully
fledged systems are present. In such situations, the Semantic Web can be likened
to a catalyst; It may not be the most powerful element in a particular system,
but without it the power of any of the other elements may never be fully
realised.
Two examples on the proposed idea of 'The Semantic Web in Systems and
Software Engineering' are presented in Section
4.1.
3.2 Ontologies as Formal Model Specifications and the
Incorporation of Such Models in Semi-Formal Languages
Despite its importance, software development still lacks adequate technology
in many areas. The development of software systems has been recognised as an
important and complex activity that requires the participation and collaboration
of physically distributed teams of people during systems development. Therefore,
a large amount of skilled manpower, time and effort is necessary when creating,
designing, writing, testing, evaluating, and maintaining software systems. The
multiplicity of stakeholders and development participants, the addition of new
features to existing services, and the heterogeneity and complexity of products
being developed require software development to be a very knowledge and
communication intensive process. Existing software development tools offer very
good support for document management and modelling, but lack of support for
communication and knowledge management. Therefore, a driving force to enhance
existing tools with communication and knowledge management is necessary.
In many respects ontologies can be simply considered as rigorous descriptive
models in their own right, being akin to existing conceptual modeling techniques
like UML class diagrams or Entity Relationship Models (ERM). As such, their
purpose is to facilitate mutual understanding between agents, be they human or
computerised, and they achieve this through explicit semantic representations
using logic-based formalisms. Typically, these formalisms come with executable
calculi that allow querying and reasoning support at runtime. This adds a number
of advantages, specifically in the areas of:
- Quality
- Requirements conformance and consistency checking.
- Rigorous typing, catogorisation and identification.
- Ease of formal specification. With the aid of graphical modeling tools
(as commonly favoured in MDA), ontologies can be built using much less
abstract user interfaces.
- Communication of requirement and intent to domain experts and developers
through:
- The ability to capture, relate and manage models of systems and
information at multiple levels and from multiple standpoints.
- Increases in semantic expresivity through coverage of concpets not embodied
in current se tools.
- Reductions in design ambiguity through.
- Unified syntax for tooling. Standard Semantic Web languages (such as OWL)
can provide unified syntax for existing formal method languages, providing
the potential for open and cooperative tooling environments for formal
methods (see Example C
presented in Section
4.2).
- Facilitation of decoupling between abstraction layers needed for
effective modelling.
- Cost
- Reduce maintenance overhead through increases in consistency.
- Increased potential for reuse, substitution and extension via accurate
content discovery on the Semantic Web.
Hence, given the semantically rich, unambiguous qualities of information
embodiment on the Semantic Web, the amenable syntax of Semantic Web languages,
and the universality of the Semantic Web's XML ancestory, there appears a
compelling argument to combine the semi-formal, model driven techniques of
Software Engineering with approaches common to Information Engineering on the
Semantic Web. This may involve the implanting of descriptive ontologies directly
into systems' design models themselves, the referencing of separate semantic
metadata artifacts by such models or a mixture of both.
What is important is that mechanisms are made available to enable
cross-referencing and checking between design descriptions and related
ontologies in a manner that can be easily engineered and maintained for the
betterment of systems' quality and cost.
3.3 Software Lifecyle Support
Some activities in the software development life cycle like requirements
elicitation, analysis, design, and testing require intense stakeholders
interactions. The use of ontologies, name spaces, and metadata can assist with
these interactions by providing standardisation of terminology, relationships,
and rules for a specific domain. This standardisation can
- Support the generation of domain models employed in different phases of
the software development life-cycle,
- Reduce problems of inconsistencies between different artefacts generated
during the development life cycle that normally occur due to the multi-perspective
of involved stakeholders,
- Facilitate the enforcement of traceability of these artefacts, which improves
quality of the software system (e.g. change impact analysis, maintenance and
evolution, component reuse, inspection, understanding),
- Augment sharing and interoperation of models created by stakeholders,
- Assist with interface semantics and software architecture descriptions;
and
- Help identifying and reusing existing components.
3.4 Corpora of Reusable Contents and the Use of Metadata
as Relational Data
Given
that The Semantic Web technologies uses triple-based data representation and
that this is merely a minimization of the representation employed in relational
database technologies, the attraction of considering the Semantic Web as a
specialised relational framework has been understood for some time. Even so, by
recognising such potential it is important to be pragmatic and consider the term
'Semantic Web' as a generalisation, having at least two specific interpretations
from a relational data standpoint. These being:
- A collection of Semantic Intra-Webs: Distinct formal ontologies,
relating to an enterprise or community of interest e.g. various collections
of researchers who take responsibility for the care and managed evolution
of such Webs in ways analogous to the Python or Linux communities. These groups,
by their very nature, will be very concerned about ontology consistency and
data quality, but may not necessarily wish for their information to be shared
as part of some larger structure.
- A singular Semantic Web: A global collection of as many Semantic
Webs (as defined above) as are public plus anything else marked up
appropriately in referencible Web space.
At current levels of Web maturity it appears reasonably plausible that strong
reliable inference could be achieved using ontologies that fall under the former
of the two above definitions. Nevertheless for ontologies associated with the
latter definition, less reliable approaches to knowledge extraction, such as
data exploration, heuristics, and 'mining', appear more realistic. This is not
to say that the concept of a global Semantic Web is not useful from a relational
data perspective, it is just that data provenance and quality issues will
undoubtedly lead to lesser degrees of information credibility across its
entirety. Even so, regardless of the fact that a singular Semantic Web might be
difficult to achieve in the short term, from a SE point of view the first
viewpoint is already highly attractive.
When debating the potential for relational data schemes under any such
definition of the Semantic Web, a significant benefit for SSE is often
overlooked: If you can describe something sufficiently well (as is the ultimate
aim on the Semantic Web), and that thing exists on the Semantic Web with a
similar level of descriptive clarity, the chances of you finding precisely that
thing are greatly increased. So, setting out to describe things better is
indirectly rewarded by the increased ability to be [semi-automatically]
discovered and to find content that is clearly equivalent or related. To be
direct, rich descriptions empower discoverability.
By
suggesting use of the Semantic Web as a system for runtime information and
artefact sharing there is also an implicit need to provide means for clearly
identifying participating objects based on composites of characterising semantic
properties (metadata in the form of name-pair/predicate-object values), and this
differs from current Semantic Web schemes for unique identification, such as FOAF sha1 (i.e. unique
identification based on a single Inverse Functional Property (IFP)). By using
composite identification the Semantic Web can be seen as a truly global
relational assembly of content and, as with every relational model, issues
dealing with composite forms of unique identification have to be addressed (i.e.
identification via composite IFP schemes)
Such
unique identification schemes should be capable of supporting both the
interlinking of broadly related ontologies into grander information corpora
(thereby implying formal similarities and relationships between discreet
ontologies and/or systems through their classifying metadata), and the
transformation of design time component associations into useful runtime
bindings. This will, therefore, provide greater potential for metadata use
across a broader spectrum of the Software Lifecycle. In so doing, this approach
carries a number of obvious implications for systems employing such techniques:
- That Semantic Web technologies could be used to formalise associations between
sub-components within a given system.
- That the Semantic Web could be used as a framework for design-time data
and component sharing, and this includes the concept of design models being
considered as valid, sharable artefacts in their own right.
- That the Semantic Web could be used as a framework for runtime data and
component sharing between discreet and disparate systems.
- That new forms of systems could be created through the integration of discreet
and disparate information and functionality with semantically similar metadata.
This appears especially appealing given current advances the areas of Web
Services and Service Oriented Architectures.
- That the Semantic Web could provide mechanisms for enabling re-usable software
to work together.
- That the Semantic Web could provide 'richer' information on which systems
and systems' components can work
If underlying metadata were used as a
basis for parameterised dynamic systems behaviour, there are further intriguing
potentials in the areas of Web Service Choreography and autonomic systems. That
is to say that Semantic Web technologies can also benefit the new paradigm of
Service-Oriented computing and service-centric systems engineering, i.e.
software systems that are constructed as compositions of autonomous services. An
important challenge of service-centric systems engineering is concerned with
service discovery in which it is necessary to identify Web services that can
fulfil the functionality of a system and compose them together. Service
discovery is required in different phases of the development life cycle of a
service-centric system, namely requirements engineering, design, and deployment.
During requirements engineering phases it is necessary to identify services that
can realise the requirements, or use the identified services to support the
definition and amendment of the system requirements, as proposed in [JMZZ
2005]. Similarly, during design specification of a service-centric system it
is important to identify services that can satisfy system constraints specified
in design models, as well as use the identified services to amend and
reformulate the design models. During development
phases, it is necessary to identify services at run-time that can replace
existing ones that are being used, but may start to fail, as shown in [SZK 2005]. In
any of the above phases, the use of Semantic Web technologies is helpful.
Semantic Web technologies such as ontologies and metadata can support the search
activity by providing classification and relationships of available services
across various registries. It can also be used to assist with terminology
disambiguation between service requests and service specifications in terms of
synonyms, hypernyms, and context when searching for services. This is even more
crucial during deployment, since it requires a high level of precision and
efficiency when trying to match requests and services.
In System Software Engineering it is also important to support systematic
validation methods such as symbolic execution, term simplification, theorem
proving, and model checking. In such settings, ontologies could be used to
support declaration of automated reasoning knowledge in addition to type and
signature information. Moreover, ontologies can also be employed to standardise
the terminology used in different models and ultimately support the sharing and
interoperation of models between different stakeholders, help model developers
to choose appropriate level of abstractions to express models of various
components of a system, and allow validations to be executed in terms of the
domains of the systems represented by those ontologies. Examples of the use of
ontologies to support the above tasks can be found in [HZ 2004a, HZ
2004b].
Semantic Web technologies can also be used to address the challenge of
interoperability in distributed systems and heterogeneous data sources such as
data warehouses [HNVV
2003]. In previous work [ZK 1999], we
have seen the use of hierarchical terminology structures (i.e. metadata) to
assist with the discovery of relevant data when dealing with heterogeneous
database systems. More recently, the work in [ZCDKS 2002]
has proposed the use of an 'information bus' that handles metadata in a generic
way and enables metadata to be used as exchanged models and ontologies, in order
to support interoperability between heterogeneous data sources. The use of
metadata and ontologies preserves the autonomy of the existing systems,
facilitate data search represented in heterogeneous data sources, provide
classification and relationships between data, and allows evolution of the
system by adding and removing data sources.
4. Examples
In this section we present examples for the proposed ideas presented in
Section 3. The examples are grouped in subsections corresponding to the
subsections of Section 3.
4.1 The Semantic Web in Systems and Software
Engineering
This section discusses two examples for the proposed idea of 'The Semantic
Web in Systems and Software Engineering'. In both cases, the applied
characterization of the Semantic Web is that of 'classification', i.e., Semantic
Web technologies and tools are used to facilitate the management of application
servers and Web services middleware, respectively.
Application servers provide many functionalities commonly needed in the
development of a complex distributed application. So far, the functionalities
have mostly been developed and managed with the help of administration tools and
corresponding configuration files, recently in XML. Though this constitutes a
very flexible way of developing and administrating a distributed application,
the disadvantage is that the conceptual model underlying the different
configurations is only implicit. Hence, its bits and pieces are difficult
to retrieve, survey, check for validity and maintain.
To remedy such problems, the ontology driven architecture (ODA) approach can
support the development and administration of software components in an
application server. The ODA approach is supplementary to MDA, where models
abstract from low-level and often platform-specific implementation details.
While MDA allows to separate conceptual concerns from
implementation-specific concerns, currently MDA has not been applied for
run-time relevant characteristics of component management, such as which version
of an application interface requires which versions of libraries. MDA requires a
compilation step preventing changes at runtime which are characteristic for
component management. Besides, an MDA itself cannot be queried or reasoned
about. Hence, there is no way to ask the system whether some configuration is
valid or whether further elements are needed. This is explained by the lack of
formal semantics of the notoriously ambiguous UML. In ODA, however, an ontology
captures properties of, relationships between, and behaviors of the components
that are required for development and administration purposes. As the ontology
is an explicit conceptual model with formal logic-based semantics, its
descriptions of components may be queried, may foresight required actions, e.g.,
preloading of indirectly required components, or may be checked to avoid
inconsistent system configurations - during development as well as during
run-time. Thus, the ODA approach retains the original flexibility in configuring
and running the application server, but it adds new capabilities for the
developer and user of the system.
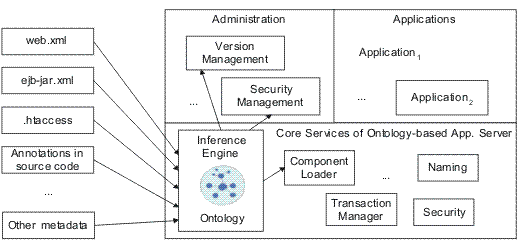 Figure 1. System architecture of the ontology-based application server.
Semantic metadata and the ontology are loaded into the inference engine.
Value-added services and tools leverage the reasoning capability embedded in the
application server.
Figure 1. System architecture of the ontology-based application server.
Semantic metadata and the ontology are loaded into the inference engine.
Value-added services and tools leverage the reasoning capability embedded in the
application server.
Figure 1 shows how an ontology-based application server could be designed.
The left side outlines potential sources, which provide input for the framework.
This includes Web and application server configuration files, deployment
descriptors or metadata files. With a standardized annotation syntax, Java 5.0
facilitates obtaining of sourcecode annotations as well. There are also first
attempts to learn ontological descriptions out of Javadoc comments [SCGM
2005]. This information is parsed and converted into semantic metadata, i.e.
metadata in terms of an according ontology. Thus, this data is now available
conforming to a harmonizing conceptual model, weaving together so far separated
aspects like security, component dependencies, version or deployment
information. The semantic metadata and the ontology are fed into the inference
engine which is embedded in the application server itself. The reasoning
capability is used by an array of tools at development and at run time. The
tools either expose a graphical user interface (e.g., security management) or
provide core functionality (e.g., the dynamic component loader) [OESV
2004]. Concrete examples along a multimedia demonstration of reasoning with
software components can be found at [OSE
2005].
Different Web Service standards, WS*,
factorize Web Service aspects into interface (WSDL), workflow (BPEL)
or security (WS-Security, WS-Policy)
descriptions. The advantages of WS* are multiple and have already benefited many
industrial cases. WS* descriptions are exchangeable and developers may use
different implementations for the same Web Service description. The
disadvantages of WS*, however, are also visible, yet: Even though the different
standards are complementary, they must overlap and one may produce models
composed of different WS* descriptions, which are inconsistent, but do not
easily reveal their inconsistencies. The reason is that there is no coherent
formal model of WS* and, thus, it is impossible to ask for conclusions that come
from integrating several WS* descriptions. Hence, discovering such Web Service
management problems or asking for other kinds of conclusions that derive from
the integration of WS* descriptions remains a purely manual task of the software
developers accompanied by little to no formal machinery.
As an example for a conclusion derived from both a BPEL and WS-Policy
description, consider the following case. Let's assume a Web shop realized with
internal and external Web Services composed and managed by a BPEL engine. After
the submission of an order, we have to check the customer's credit card for
validity depending on the credit card type (VISA, MasterCard etc.). We assume
that credit card providers offer this functionality via Web Services. The
corresponding BPEL process checkAccount thus invokes one of the
provider's Web Services depending on the customer's credit card. The example
below shows a snippet of the BPEL process definition.
...
<process name="checkAccount">
<switch ...>
<case condition="getVariableData('creditcard')='VISA'">
<invoke partnerLink="toVISA" portType="visa:CCPortType" operation="checkCard"...>
</invoke>
</case>
<case condition="getVariableData('creditcard')='MasterCard'">
<invoke partnerLink="toMastercard" portType="mastercard:CCPortType" operation="validateCardData"...>
</invoke>
</case>
...
</switch>
</process>
...
BPEL document of Web Shop |
Suppose now that the Web Service of one credit card provider, say MasterCard,
only accepts authenticated invocations conforming to Kerberos or X509. It states
such policies in a corresponding WS-Policy document like the one sketched below.
The invocation will fail unless the developer ensures that the policies are met.
That means the developer has to check the policies manually at development time
or has to implement this functionality to react to policies at runtime.
...
<wsp:Policy>
<wsp:ExactlyOne>
<wsse:SecurityToken>
<wsse:TokenType>
wsse:Kerberosv5TGT
</wsse:TokenType>
</wsse:SecurityToken>
<wsse:SecurityToken>
<wsse:TokenType>
wsse:X509v3
</wsse:TokenType>
</wsse:SecurityToken>
</wsp:ExactlyOne>
</wsp:Policy>
...
External WS-Policy document |
As we may recognize from this small example, it would desirable to automate -
or at least facilitate - such manual management tasks. Therefore, we postulate
semantic management of Web Services to support developers and
administrators who must cope with the complexity of Web Service integration and
WS* descriptions. These two groups of users have the need to predict or observe
how Web Services interact, (might) get into conflict, (might) behave, etc. It
will be very useful for them to query a system for semantic management of Web
Services that integrates aspects from multiple WS* descriptions. Ontologies are
the obvious choice for the conceptual information integration because of their
formal semantics. In addition, corresponding inference engines allow for
reasoning and querying with semantic descriptions. [OLES
2005]
Coming back to our example, we could harvest available information for each
of the services and construct two semantic service descriptions. For our
internal service, we parse and integrate the workflow graph of the BPEL file.
Existing OWL-DL ontologies (e.g. the Ontology of Plans cf. [GBCL
2004]) can be reused for that purpose. The ontology allows to associate
invocations of external services with their respective semantic description. In
the example, validateCardData is associated to the Mastercard service
description via externallyInvokes. It suffices to state that there
exists a policy for the Mastercard service in its respective description. That
enables us to pose a simply query and infer that there is one externally invoked
service that cannot be used without conforming to a policy. Thus, the developer
is alerted to this fact and required to react (at development or deployment
time). Two OWL-DL snippets of the service descriptions are depicted below:
<rdf:RDF xmlns:ns="http://internalService#">
<owl:Ontology rdf:about=""/>
<rdf:Description rdf:about="http://internalService#InternalServiceDescription"
rdf:type="ServiceDescription">
<component rdf:resource="http://internalService#InternalPlanDescription"/>
</rdf:Description>
<rdf:Description rdf:about="http://internalService#InternalPlanDescription"
rdf:type="PlanDescription">
<component rdf:resource="http://internalService#SwitchTask"/>
</rdf:Description>
<rdf:Description rdf:about="http://internalService#SwitchTask" rdf:type="Task">
<successor rdf:resource="http://internalService#validateCardData"/>
</rdf:Description>
<rdf:Description rdf:about="http://internalService#validateCardData" rdf:type="Task">
<externallyInvokes rdf:resource="http://externalService#MasterCardServiceDescription"/>
</rdf:Description>
</rdf:RDF>
OWL description of our own Web service
|
<rdf:RDF xmlns:ns="http://externalService#">
<owl:Ontology rdf:about=""/>
<rdf:Description rdf:about="http://externalService#MasterCardServiceDescription"
rdf:type="ServiceDescription">
<component rdf:resource="http://externalService#MasterCardPolicy"/>
</rdf:Description>
<rdf:Description rdf:about="http://externalService#MasterCardPolicy"
rdf:type="PolicyDescription">
</rdf:Description>
</rdf:RDF>
OWL description of the external Web service
|
It is possible to consider further advantages and more complex examples:
checking for cycles in workflow, situations where large invocation sequences
occur, or consideration of further aspects like the WSDL interface description.
In further improvements it may be possible to consider formalization of the
policy itself to support conformity checking. A target platform for integrating
could be an application server, a workflow engine or a software IDE. In
principle, ontology infrastructure has to be added and relevant information
obtained from WS* descriptions.
The approach of semantic web service management is supplementary to the OASIS
Web
Services Distributed Management (WSDM) recommendation which defines how to
manage Web services as resources and how to describe and access that
manageability.
4.2 Ontologies as Formal Model
Specifications and the Incorporation of Such Models in Semi-Formal
Languages
According to [Brown
2004], a formal underpinning for describing models facilitates meaningful
integration and transformation among models, and is the basis for automation
through tools. However, in existing MDA practice, semi-formal metamodels instead
of formal specification languages are used as such formal underpinnings for
describing models. An obvious reason is that, unlike UML, the industrial effort
for standardising diagramatic notations, a single dominating formal
specification language does not exist. Furthermore, different specifaction
languages are designed for different purposes; e.g., B/VDM/Z* are
designed for modelling data and states, while CSP/CCS/π-calculus**
are designed for modelling behaviors and interactions.
To solve the problem, we can use ontologies as formal metamodels to describe
various formal specification languages; moreover, the standard Semantic Web
ontology language OWL can provide unified syntax. Semantic links among different
models are explicitly specified by ontologies and form the basis of automation
through tools in a Semantic Web-base enviroment. Based on these semantic links,
various existing proposals of integrating formal specification languages can be
supported in such enviroments.
[Wang
2004] briefly describes such an Semantic Web-based enviroment for semantic
link among models, using DAML+OIL (instead of OWL). Examples of semantic links
include assertions that Object-Z classes are (treated as) equivalent to CSP
processes and that Object-Z operations are equivalent to CSP events.
Feature modeling plays an important role in domain engineering, which is a
software reuse approach that focuses on a particular application domain.
Examples of different domains are word processing, device driver for network
adapters, inventory management systems, etc. Features are prominent and
distinctive user visible characteristic of a system. Systems in a domain share
common features and also differ in certain features. A feature model consists of
a feature diagram and other associated information (such as rationale,
constraints and dependency rules). However, the lack of a formal semantics and
reasoning support of feature models has hindered the development of this area.
Industrial experiences show that methods and tools that can support feature
model analysis are badly appreciated.
A feature diagram provides a graphical tree-like notation that shows the
hierarchical organization of features. The root of the tree represents a concept
node, the instances of which are systems support the feature; the other nodes
are sub-features of the root. There are four kinds of sub-features (see Figure
2).
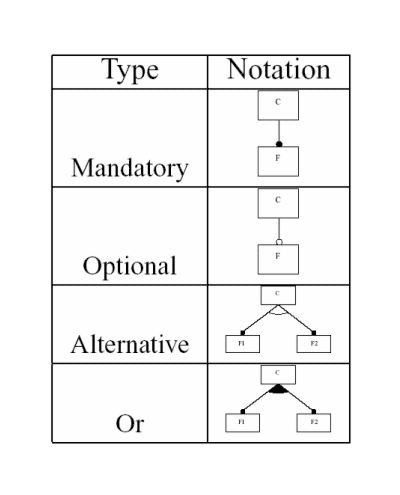 Figure 2. Types of sub-features.
Figure 2. Types of sub-features.
- Mandatory: The feature must be included into the description of a
concept instance.
- Optional: The feature may or may not be included into the description
of a concept instance.
- Alternative: Exactly one feature from a set of features can be included
into the description of a concept instance.
- Or: One or more features from a set of features can be included
into the description of a concept instance.
A feature diagram itself cannot capture all the inter-dependencies among
features. We have identified two additional relations among features: requires
and excludes.
- Requires: The presence of some feature in a configuration requires
the presence of some other features.
- Excludes: The presence of some feature excludes the presence of
some other features.
We can use OWL to represent all the them (see the OWL codes below). For
example, we can represent "F is a mandatory sub-feature of C" with the following
OWL DL axiom
<owl:Class rdf:about="C"/>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasF"><owl:someValuesFrom rdf:resource="#F">
</owl:Restriction>
</owl:Class>
|
and represent "F is a optional sub-feature of C" with the following OWL DL
axiom.
<owl:Class rdf:about="F"/>
<owl:Restriction>
<owl:onProperty rdf:resource="#hasC"><owl:someValuesFrom rdf:resource="#C">
</owl:Restriction>
</owl:Class>
|
By representing
feature models as OWL axioms, the consistency of feature configurations can be
automatically checked by Description Logic-based Semantic Web reasoning engines.
More details of OWL representations of feature models as well as corresponding
tool support can be found in [WFSZP
2005].
It is apparent that the descriptive advantages of an ontological view of the
world, as outlined by the Semantic Web, are appealing to the field of Systems
and Software Engineering. The challenge now is to move from research towards
adoption, both in tooling and practice. This will undoubtedly be an arduous
journey and may mean some significant concessions from both sides to produce
what will almost certainly be a composite approach, combining elements from both
existing Software Engineering practice and emerging Semantic Web fields.
Stronger semantics should, quite correctly, act as a catalyst in Software
Engineering's advance. For real progress to be made, however, those involved
must recognise tools like the UML to be evolving entities if their ultimate
survival is to be assured. New ideas and significant challenges to current
thinking are therefore right and proper and should be seriously debated in the
appropriate manner. Such new ideas include Design by Contract and new variants
of the UML in which its Object Constraint Language (OCL) is strengthened, or
even replaced, by Semantic Web compliant languages or Simple Common Logic. Even
more radical ideas exist relating to the role of abstraction or meta-levels in
the practice of modelling complex multidimensional systems. Furthermore, there
are those of freely talk about the concept of meta-systems; huge semantically
rich composites of systems in their own right, rigorously defined and
interconnected, that will autonomically form and self-regulate for a recognised
purpose(s). Much more work is needed in such areas, but their potential has
already been recognised and the volume of related publication is most certainly
on the rise. What remains now is to flesh out the detail behind such ideas
through strong academic, standards and industrial liasons.
Special thanks are due to Prof Cliff Jones (University
of Newcastle) for his kind advice during the preparation of this note. David
Wood, Jim Hendler, and Jeremy Carrol contributed useful reviews. Rudi Studer for
hints on the background section.
- [AXML 2003]
- Active XML
- [Brown 2004]
- An Introduction
to Model Driven Architecture - Part I: MDA and Today's Systems.
Alan Brown, IBM.
- [GBCL 2004]
- Task Taxonomies for Knowledge Content. Aldo Gangemi, Stefano
Borgo, Carola Catenacci, Jos Lehmann. Technical Report. Metokis Deliverable
D07. June 2004.
- [HNVV 2003]
- Thesus: Organising Web Document Collections based on Semantics and Clustering,
M. Halkidi, B. Nguyen, I. Varlamis and M. Vazirgiannis, Journal on Very Large
Databases, Special Edition on the Semantic Web, November 2003.
- [HZ 2004a]
- Behavioral
Models as Service Descriptions, 2nd International Conference on Service
Oriented Computing , R.J. Hall and A. Zisman, ICSOC 2004, New York,
November 2004.
- [HZ 2004b]
- OMML:
A Behavioural Model Interchange Format . R.J. Hall and A. Zisman,12th
IEEE International Conference in Requirements Engineering (RE'2004), Japan,
September 2004.
- [JMZZ 2005]
- How Service Centric Systems Change the Requirements Process.
S.V. Jones, N.A.M. Maiden, K. Zachos, and X. Zhu. In Proc. Of REFSQ'2005 Workshop,
in conjunction with CAiSE 2005, Portugal, 2005.
- [OESV 2004]
- Developing and Managing Software Components in an Ontology-based
Application Server. Daniel Oberle, Andreas Eberhart, Steffen Staab,
Raphael Volz. In Hans-Arno Jacobsen, Middleware 2004, ACM/IFIP/USENIX 5th
International Middleware Conference, Toronto, Ontario, Canada, volume 3231
of LNCS, pp. 459-478. Springer, 2004.
- [OLES 2005]
- Semantic Management
of Web Services. Daniel Oberle, Steffen Lamparter, Andreas Eberhart,
Steffen Staab. 3rd International Conference on Service Oriented Computing,
ICSOC 2005, Amsterdam, December 2005.
- [OSE 2005]
- Towards Semantic Middleware for Web Application Development.
Daniel Oberle, Steffen Staab, Andreas Eberhart. IEEE Distributed Systems Online.
February 2005.
- [Pietro-Diaz 1991]
- Implementing Faceted Classification for Software Reuse. R.
Pietro-Diaz, Communications of the ACM. Special issue on software engineering,
34(5):88, May 1991.
- [Pohl 1999]
- Requirements Traceability - Models of the Development World.
Pohl, K.: In: M. Jarke; C. Rolland; A. Sutcliffe: The NATURE of Requiremtents
Engineering. Shaker Verlag, Aachen 1999.
- [SCGM 2005]
- Learning Domain Ontologies for Web Service Descriptions: an Experiment
in Bioinformatics. Sabou M., Wroe C., Goble C. and Mishne G. In Proceeedings
of the 14th International World Wide Web Conference (WWW2005), Chiba, Japan,
10-14 May, 2005
- [SEKE 2005]
- 17th International Conference on Software Engineering and Knowledge
Engineering, http://www.ksi.edu/seke/seke05.html.
- [SZK 2005]
- A Service Discovery Framework for Service Centric Systems ,G.
Spanoudakis, A. Zisman and A. Kozlenkov, IEEE International Conference on
Services Computing (SCC 2005), Florida, USA, July 2005.
- [Wang 2004]
- Semantic Web and
Formal Design Methods. Hai Wang. PhD thesis, National University
of Singapore.
- [WFSZP 2005]
- A Semantic Web
Approach to Feature Modeling and Verification. Hai Wang, LI Yuan
Fang, Jing Sun, Hongyu Zhang and Jeff Z. Pan. In Proc. of the International
Workshop on Semantic Web Enabled Software Engineering (SWESE). 2005.
- [ZCDKS 2002]
- Using
Web Services to Interoperate Data at the FAO , A. Zisman, J. Chelsom,
N. Dinsey, S. Katz and F. Servan,DC-2002 - Metadata for e-Communities: Supporting
Diversity and Convergence, Florence, October 2002. (This paper was also presented
in XML Conference and Exposition 2002, Baltimore, USA, December 2002).
- [ZK 1999]
- An
Approach to Interoperation between Autonomous Database Systems ,A.
Zisman and J. Kramer, Distributed Systems Engineering Journal 6, 1999,
135-148.
Appendix A. Informative References
- [AJWH 2003]
- Managing Software
Engineering Knowledge. A.Aurum,
R. Jeffery, C. Wohlin, M. Hadzic. Springer Verlag, 2003.
- [Atkinson 2004]
- On the Unification of MDA and Web-based Knowledge Representation
Technologies. Colin Atkinson. 1st International Workshop on the
Model-Driven Semantic Web (MDSW2004).
- [CGL 2004]
- Issues in Mapping Metamodels in the Ontology Definition Metamodel.
Robert M. Colomb, Anna Gerber, Michael Lawley. 1st International Workshop
on the Model-Driven Semantic Web (MDSW2004).
- [ChKe 2004]
- Major Influences on the Design of the ODM. Daniel T.
Chang and Elisa Kendall. 1st International Workshop on the Model-Driven Semantic
Web (MDSW2004).
- [ChKe 2004b]
- Metamodels for RDF Schema and OWL. Daniel T. Chang
and Elisa Kendall. 1st International Workshop on the Model-Driven Semantic
Web (MDSW2004).
- [CrGe 2005]
- Situation and Identity - A Generalisation of Inverse Functional
Properties. Tom Croucher, University of Sunderland and Joe Geldart,
University of Durham.
- [EmHa 2005]
- A Description Logic for Use as the ODM Core. Patrick
Emery and Lewis Hart. 1st International Workshop on the Model-Driven Semantic
Web (MDSW2004).
- [EmHa 2005b]
- Including Topic Maps in the Ontology Definition Meta-Model.
Patrick Emery and Lewis Hart. 1st International Workshop on the Model-Driven
Semantic Web (MDSW2004).
- [FHKM 2004]
- The Model Driven Semantic Web. David Frankel, Pat Hayes,
Elisa Kendall and Deborah McGuinness. 1st International Workshop on the Model-Driven
Semantic Web (MDSW2004).
- [FHKM 2004b]
- Simple Common Logic: A Constraint Language for the ODM .
David Frankel, Pat Hayes, Elisa Kendall and Deborah McGuinness. 1st International
Workshop on the Model-Driven Semantic Web (MDSW2004).
- [GaTi 2004]
- An MDA-Based Approach for Facilitating Adoption of Semantic Web
Service Technology. Gerald C. Gannod and John T.E. Timm. 1st International
Workshop on the Model-Driven Semantic Web (MDSW2004).
- [GSNGW 2004]
- Model Driven Middleware. Aniruddha Gokhale and Douglas C. Schmidt
and Balachandran Natarajan and Jeff Gray and Nanbor Wang. In Q.H. Mahmoud
(ed.): Middleware for Communications, Chapter 7, 163-187, Wiley, 2004
- [Guha 2004]
- Object
Co-identification on the Semantic Web. R. V. Guha, IBM Research,
Almaden.
- [HS 2004]
- Tools for design of composite Web services, by Richard Hull and Jianwen
Su. SIGMOD 2004.
- [Knublauch 2004]
- Ontology Driven Software Development in the Context of the Semantic
Web: An Example, Scenario with Protégé/OWL. Holger Knublauch. 1st
International Workshop on the Model-Driven Semantic Web (MDSW2004) Enabling
Knowledge Representation and MDA® Technologies to Work Together.
- [MSUW 2004]
- MDA Distilled - Principles of Model-Driven Architectures. Stephan
J. Mellor, Kendall Scott, Axel Uhl, Dirk Weese. Addison-Wesley, 2004.
- [Oberle 2005]
- Semantic Management of Middleware. Daniel Oberle. In
A. Sheth, R. Jainn (eds.) The Semantic Web and Beyond, volume I, Springer
2005.
- [PeSc 2003]
- Curing the Web's Identity Crisis. S. Pepper and S. Schwab.
Technical report, Ontopia, 2003.
- [SKC 2001]
- Handbook of Software Engineering
and Knowledge Engineering, Vol. 1, S.K. Chang (editor),World
Scientific, (ISBN: 981-02-4973-X), 2001
- [Tetlow 2004]
- SOA, Glial and the Autonomic Semantic Web Machine - Tools for
Handling Complexity? Philip Tetlow, IBM, UK.
- [Wallace 2004]
- Experiences and Issues in Converting Data and Object Modeling Languages
to OWL. Evan Wallace. 1st International Workshop on the Model-Driven
Semantic Web (MDSW2004).
- [XLZMP* 2004]
- SemanticWare: An EMF-Compatible RDF Infrastructure.
Guo Tong Xie, Shixia Liu, Zhuo Zhang, Li Ma, Yue Pan, Li Zhang, Zhong Su, Li
Qin Shen. 1st International Workshop on the Model-Driven Semantic Web
(MDSW2004).
- Specification and design representation schemes, both formal and informal;
- Descriptions and models of the development process;
- Tools and environments to support software development;
- designers and implementors, and cognitive properties of representation schemes,
programming and programming languages;
- Software development methods, analysis and validation;
- Requirements elicitation,
- Acquisition and formalization;
- Software quality and metrics;
- Software reuse and adaptation;
- Animation and execution of specifications and designs;
- Domain modelling and analysis;
- Software visualization;
- Software object management;
- Development of user interfaces;
- Group and team work in software engineering;
- Development of distributed, real-time, embedded and composite systems;
- Systems integration;
- Software evolution and maintenance;
- System testing;
- Reverse engineering and program understanding; documentation and program
explanation;
- Software complexity and emergence;
- Network Theory
- Web Bow Tie Models
* VDM is an abbreviation
for "Vienna Development Method" specification language.
**CSP is
abbreviated for "Communication Sequential Processes", CCS
is abbreviated for "Calculus for Communicating Systems".