
Paper to be reviewed for "Annotation for the Semantic Web" book to appear in the series "Frontiers in Artificial Intelligence and Applications" by IOS Press.
Marja-Riitta Koivunen and Ralph R. Swick
{marja,swick}@w3.org
World Wide Web Consortium
MIT Laboratory for Computer Science
Annotea is a metadata based annotation infrastucture that supports information sharing through annotations. Because it uses W3C Semantic Web technologies, specifically RDF, it can be easily extended to support many kinds of annotations and annotation-like collaborative applications that share metadata about Web documents.
Annotea annotations can be attached to any XML-based document, such as XHTML and SVG documents, or to annotations themselves, without modifying the original documents. Annotea is completely open and is built on top of standard W3C technologies. The annotations are modelled as RDF metadata and XPointer and XPath are used to attach the annotations to documents. Annotations can be shared by storing them into annotation servers and queried by using annotation capable clients, such as the W3C Amaya editor/browser. The HTTP protocol is used for all the data exchange between a client and servers.
In this paper, we describe three user scenarios and discuss how they benefit from this metadata based annotation infrastructure. We explain how a basic annotation schema can be extended to support new scenarios. We also describe and evaluate some other features and modifications that are useful when implementing these scenarios. The metadata infrastructure easily supports the needs of the different applications on the schema level. Currently the most laborious part in the scenarios is the design and implementation of the additional user interface to accompany a schema change. The data store has proven to be very flexible, requiring very few changes as we incorporate new data into our annotations.
Keywords: Semantic Web, annotation infrastructure, metadata, collaboration scenarios
Annotea [Annotea 2001] is a metadata based annotation infrastucture that can support very rich communications about the Web documents without requiring write access to the annotated document. A user can attach an annotation to a Web document and a collaborator will see the annotation when he or she retrieves the same Web document (see Figure 1) as long as they share a common annotation server. Because Annotea uses Semantic Web technologies it can be easily extended to support the changing annotation needs of a group and to support other collaborative applications similar to annotations that share metadata about Web documents.
Figure 1: A user shares a comment with another user by annotating a Web document.
Annotea annotations are metadata associated with a Web document or parts of a Web document. This metadata uses vocabularies grounded in semantically rich ontologies that are themselves published in the Web. In addition, the association between the metadata and the Web document is itself described through extensible semantics. By enabling collaborative groups to declare their own specializations of a generic "annotates" relationship, Annotea encourages the recording and sharing of explicit semantics. The Annotea metadata infrastructure opens many possibilities that can be extended beyond the basic annotation capabilities [KCAP 2001].
Section 2 in this paper describes a simple scenario showing how basic annotations can support collaboration and then introduces two additional scenarios illustrating extensions. Section 3 explains the basic Annotea metadata infrastructure in more detail and then explains the features that are needed to support the additional scenarios in Section 2. Finally Section 4 explains the current implementation status and possible future work.
The following subsections describe three annotation scenarios. The first scenario explains the use of annotations for basic collaboration, the second scenario uses annotations as shared bookmarks, and the last scenario examines the use of annotations for communicating evaluation results. Currently, Annotea offers implementations for the annotations and replies discussed in the basic collaboration scenario; the other scenarios describe possible extensions that we are in the process of implementing or with which we have done some preliminary experimenting.
A group of students in a seminar course are writing a report on the communication of whales. They collaborate by using the Web to publish new material they create themselves and to share hypertext links to existing reference material they find on the Web. They also annotate the material they uncover without regard to read-only or read-write access rights as long as they share the same annotation (metadata) server dedicated for the seminar.
Only users subscribing to the seminar annotation servers can see the students' annotations. It is easy for the users to select the server when they want to work on the course material. As they visit an annotated document they see annotation icons embedded in the document. They can open these annotations and add replies to them if they wish. Figure 2 presents one of the annotations made by the group using the Amaya client. The annotation is presented to other students with a pencil icon, which can be opened to an annotation window containing the content of the annotation and any replies it might have. The replies can also be opened from the reply thread view to show their content in a reply window.
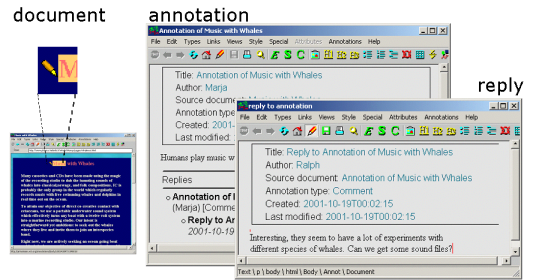
Figure 2: A selected annotation is first opened in an annotation window showing a reply thread view at the bottom. Then a selected reply is opened in a reply window.
As the students read reference documents they find in the Web, they use annotations to mark or question unclear text, reply to these questions, point out interesting perspectives, add keywords or categories, and share other general comments with each other. They use the available annotation and reply types with some new annotation types they have defined themselves. Replies often start fruitful discussions in the context of the reference documents.
The students create a list of interesting reference documents in its own summary document and gather some discussions from the reply threads into this summary documents that again can be annotated. When they add a document to the summary document they also annotate it by using a special annotation type with a special icon defined by the group. The idea is that when a student looks at the reference document later he or she can immediately see from the presence of the annotation that this document has already been included in the summary.

Figure 3: Annotations can be used to attach topics to Web documents and offer a) a document context view or a b) a topic hierarchy view to a list of annotated documents.
A W3C Working Group (AWG1) is a geographically distributed group of people collaborating to develop a specification for a new or improved piece of core Web technology. The group develops working drafts of documents, maintains a list of open issues and their explanations, and collects background material and develops discussion material about the issues before they are solved and incorporated into the working drafts. As the discussions about the issues advance some issues may be divided into subissues so that the issues form a hierarchy.
Annotations can support the discussions by letting AWG members easily mark and comment the material related to the issues. When other AWG members visit the documents annotated by their peers they easily see in the document's context what the controversial parts are. In addition, the group can file the annotated documents or the annotations themselves under certain topics related to an issue hierarchy and offer an alternative view of the annotations.
Annotations with topics can be automatically presented in a topic hierarchy based on topic metadata. The users may select a view of the AWG comments that are sorted automatically under the AWG issues as presented in Figure 3b or 4. There is no need for an AWG member to sort and edit manually a shared document of links under selected topics or send e-mail to a dedicated editor.
In a sense, the annotations with topics can be thought to be bookmarks as they also mark interesting documents or parts of documents and catalog them. Therefore the view of topic hierarchies can be very similar to the views used for bookmark or favorites hierarchies in today's browsers (see Figure 4).
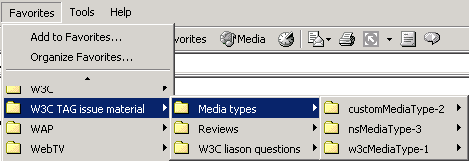
Figure 4: A sample hierarchical presentation of bookmark categories.
Topic is just one of a variety of such extensions that the group could decide to store with their annotation metadata. The AWG members could also benefit from adding some status information about an issue to the comments related to issues. It is also possible to annotate an annotation or a reply comment, for example, with a link to one or more messages in a mail archive containing further discussion of the issue.
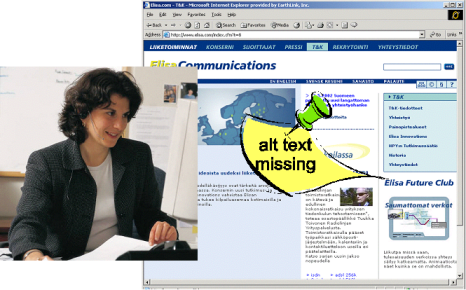
Figure 6: Anna marks the accessibility defects in developers' draft document by using annotations.
Annotations can also be used to attach either machine-generated or manually-generated evaluations to a document. Anna, an accessibility specialist in her company, uses annotations to remind the developers that the physical and cognitive abilities of the readers of her company's Web documents may vary and therefore it is important that they are accessible.
Anna assesses the markup used in her company's Web documents by using the Web Accessibility Initiative [WAI] guidelines and some automatic accessibility evaluation tools that rely on EARL [EARL 2001]. EARL is a metadata language that can express accessibility problems in a document, citing by URI the specific guideline that describes the accessibility issue. In Figure 6 Anna has attached an annotation to an image stating that the document does not have alternative text for the image and therefore is not accessible to users who cannot see the image.
Anna stores the EARL analysis of each document in her company's annotation server and adds to the server some inferencing rules that represent a transformation from the EARL vocabulary to the annotation vocabulary. As a result of processing the inferencing rules the developers can see the EARL report items as annotations in the document contexts and can use replies to address the issues and mark them as fixed.
The basic Annotea infrastructure, as we have implemented it, is presented in Figure 7. When a user attaches an annotation to a Web document the annotation metadata is stored on one or more annotation servers. When the annotated Web document is visited by a user using an Annotea capable client the client queries annotations related to the Web document from the annotation servers to which the user subscribes.
Annotations are written to the server using the HTTP POST and PUT requests and queried using the HTTP GET request for all queries. The simple and most common query is a request for "all" annotations of a document or for a complete reply thread starting from a given annotation. This query is implemented as a simple HTTP GET with a URI parameter giving the name of the Web document or the root annotation. More complex queries are specified through a generic RDF query language named 'Algae'. Algae queries are themselves passed to an Annotea server by URI-encoding them into an HTTP GET.
After the annotations are retrieved from the server they can be presented to the user in several ways. In our Amaya [Amaya] client they appear in the context of the Web document as icons that, when selected by the user, render the annotation content in a separate pop-up window. Another client could query and present the metadata information in other ways; for example, embedding the annotation content in-line in the document [Arakne 2002].
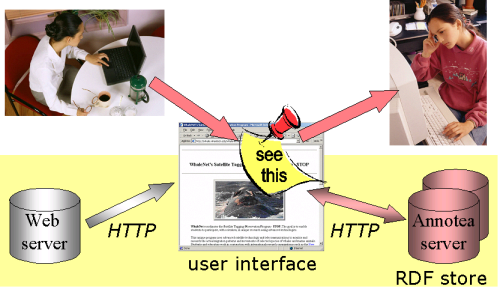
Figure 7: Annotea infrastucture
Annotea uses W3C technologies when possible. Each Annotea server is a generic RDF store. The HTTP protocol is used to store and retrieve the RDF/XML [RDF 1999] metadata describing annotations from the Annotea servers. The XPointer standard is used to refer to the part of the document being annotated and Xlink is used to present the annotations on a Web document.
The metadata infrastructure of the Annotea project makes it easy to support the annotation scenarios presented above. The basic annotation schema and the extensions needed for the previous scenarios are discussed in the following sections.
In the first scenario, the students annotate Web documents and use the reply threads as supported by the Annotea infrastructure. The annotations and the replies in these scenarios are metadata described with RDF.
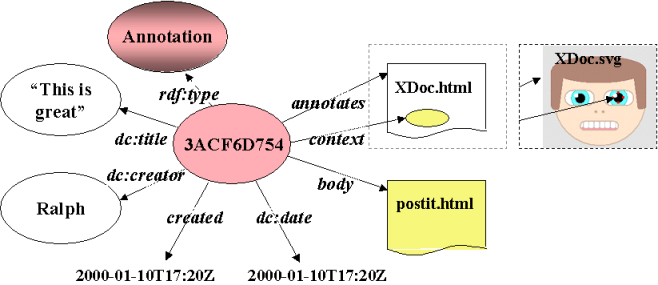
Figure 8: An instance of an annotation using the basic Annotea annotation schema while annotating an XHTML or a SVG document
Figure 8 presents an instance of a basic annotation schema. It uses properties from multiple RDF schemas [RDFS 2000] e.g. Dublin Core (dc:) [DCMI 1999]. Annotations can apply to a whole document or just a part of it and the document being annotated can be any XML document e.g. an XHTML document (illustrated by the first dotted-outline region in Figure 8) or an SVG image (as illustrated by the second dotted-outline region). The annotates property relates an instance of an annotation to the annotated document and the context property refers to the actual location of the annotation within the annotated document. The annotation content written by the user is stored in the body property and a descriptive annotation title is stored in the dc:title property. The other properties further describe the annotation.
Annotea annotations are usually not just plain instances of rdf:type Annotation. The user may choose a special annotation type from seven predefined annotation subclasses: Advice, Change, Comment, Example, Explanation, Question, and SeeAlso. By default the annotations are of type Comment.
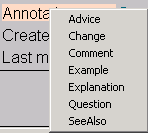
Figure 9: Predefined Annotation subtypes in a menu
The annotation types used in Annotea are not fixed to these predefined types. A collaborating group can easily extend Annotea and define their own annotation types by writing a new RDF schema. To inform the client of the new annotation types the schema is added to the client's list of used annotation schemas. The client reads the schema definitions and presents all annotation types in a menu in the user interface (see Figure 9). These annotation types are used in addition to the predefined types. If the predefined annotations are not needed they can be commented out on that list.
In the future, we would also like to let users easily use and manipulate new properties related to the annotation types and attach a user interface profile that an application can use to learn how to present these new properties without requiring programming of the application.
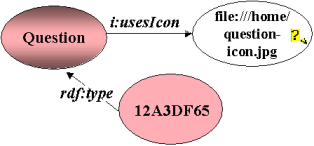
Figure 10 : Adding an icon for all annotations of type Question.
Another way to extend the annotation definitions is to add a different icon for each annotation type. Figure 10 presents an instance of an annotation type Question with an added icon definition. When this icon definition is added to Annotea, the user interface changes so that it uses the new icons instead of the generic pencil icon.
Right now Amaya only presents the icons attached to the annotation types but in the future we could as well define RDF rules that tell which icon to use in which context. For example, the user may want to use a different icon for all annotations in a specific server or a special icon for a selected user and otherwise use the generic icons for annotation types.
Many users want to be able to add replies to annotations and see the replies presented as a discussion thread. For that purpose Annotea is extended to include a reply concept that can be attached to an annotation or to another reply. The discussion threads consisting of replies always start from an annotation.
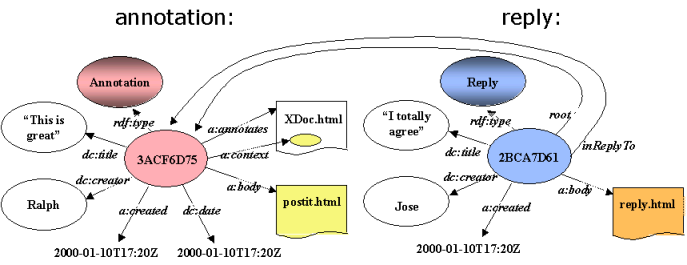
Figure 11: An instance of a reply using the Annotea reply schema attached to an annotation
Figure 11 presents an instance of a reply using the Annotea reply schema. The figure illustrates two new properties, the inReplyTo and root property. The inReplyTo property declares the annotation or reply that is the previous one in the thread. The root property points to the first annotation in the thread. The root property is used for performance optimization; it permits us to find replies related to a particular annotation more easily without having to do more chaining.
The reply schema looks very similar to an annotation schema and in a way it could be defined as an annotation subtype. However, it has enough of its own characteristics from the user's point of view that it makes sense to define it as a totally new concept with its own subtypes that only reuses the Annotation properties. For instance, we don't want to list the subtypes of reply in the same menu as the annotation subtypes. If further deployment experience shows that it would be better to declare Reply to be a subclass of Annotation it will be easy to add the subtype information to the reply schema.
The generic metadata-based design of our annotation server and the query language has made it easy to incorporate the additional reply properties; the bulk of the work is in extending the user interface capabilities so that our Amaya client will know how to show the reply thread in the end of the annotation window and how to present the reply in a reply window. In the future, we could have a method in a library that knows how to present thread-like objects with a parent and a root property and just map our reply schema to that presentation in a similar way that presentation of collections is done in Haystack [Haystack 2002].
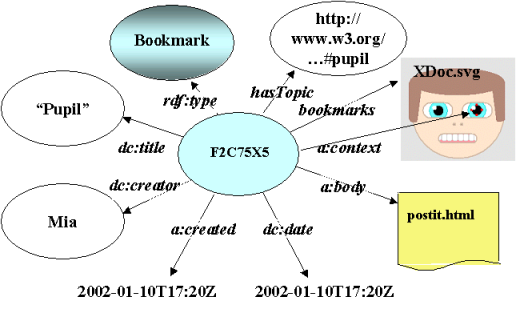
Figure 12: An instance of a bookmark using the bookmark schema attached to an SVG document.
When we want to add topics to documents in our annotation framework we just need to add a new property to our annotation model. The generic metadata approach naturally supports this in various ways. RDF and RDF Schema provide the basic mechanism to declare new properties. In addition, the DAML+OIL and WebOnt ontology construction vocabularies [DAML 2001] provides a framework for describing new properties with precise semantics and placing those semantics in the Web.
First we define a new property hasTopic that can be used to assign a topic. An Annotea server will store and retrieve this new property without modification when the property is attached to an annotation. However, the client user interface needs modification to be able to present the property to the user in an understandable way and let the user modify it. The user interface for presenting annotations by topic can be very flexible; the same data can be viewed as annotations in the context of an annotated document or as a hierarchical view by topic with bookmark-style links to the annotated documents.
Although annotations and bookmarks have nearly identical implementations within the data store, from the user's perspective it is common to present these as separate concepts. This separation simplifies the question of how in the UI to capture the user's desire to view a hierarchical presentation. Figure 12 illustrates an instance of a bookmark, citing a document (a diagram in this case) via the bookmarks property and using the hasTopic property to categorize the bookmark (and, by inference, the document). Other metadata about the bookmark is described using the same properties that are used for annotations. Figure 13 illustrates a topic hierarchy in which the specific topic of Figure 12 might reside. A traditional topic view would reproduce the graph of Figure 13 in a hierarchical presentation.
We separate our Bookmark class from our Annotation class for the same reasons that we separated our Reply class. While bookmarks share many metadata properties with annotations (and replies), we propose that one is not a superset of the other. This can be changed in the future when we learn more about the clients' needs for the user interface. In the future we are also hoping to define a presentation profile for new concepts and properties that the client can use to dynamically adjust the user interface when new metadata needs to be added.
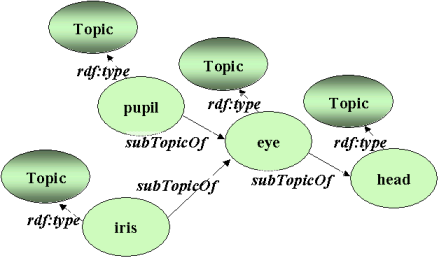
Figure 13: An instance of a sample topic hierarchy describing animal heads.
To present the resources under the topic hierarchies we need to be able to define topic hierarchies. At times the users also need to be able to query all the resources under a certain topic, whether the document is annotated explicitly as having that topic or is annotated as having a subtopic one or more levels down below the requested topic. For instance, when an AWG participant (from scenario 2.2) is looking for background material related to a certain issue he might want to get also the material related to the subissues of that issue.
As topic hierarchies can be modified dynamically by the user, we chose to optimize the query operation by adding a simple forward-chaining inferencing mechanism to our annotation server. The following inference rule is evaluated to determine during query execution whether or not a document is associated with a general-topic:
We can also add a more general inference rule that states that a topic is associated also with its subtopics at any level:
After these rules it is possible to query e.g. all head related bookmarks associated with the topic Eye and get also the bookmarks under the topics Pupil or Iris (see the topic hierarchy in Figure 13). Our Algae language implementation permits rules like these to be stored as RDF data in the database or used one-time for a single query and then discarded. When the rules are stored in the database they become part of the knowledge used in all subsequent queries. We have not yet implemented a mechanism for identifying the source of a fact in the database when it came from such an inference rule. This mechanism would be part of a general mechanism to exchange provenance metadata and would be the method by which a query could 'turn off' or disable certain inferences.
Annotations can be used to present automatically generated report items, such as accessibility evaluation items or markup validation items. If the report items are described in the metadata format it is straight-forward to map them to an annotation schema. For instance, the EARL report item reporting an accessibility problem has semantics that map easily into an annotation of a part or the whole of the evaluated Web document. This mapping can be expressed as a collection of inference rules over the properties produced by the EARL tools.
The generic metadata framework provides the necessary flexibility to decide on a case by case basis whether to archive, delete, or revise annotations when a document is reprocessed through the evaluation tool. The tool can maintain state information for successive runs in the same metadata store.
Annotea is deployed for world-wide use. The W3C runs both public and closed (work group) Annotea services. The public service is intended for demonstration purposes. Any Web user with an e-mail address can obtain permission to write to the public service. Hundreds of such users have applied for and been granted this access. The Annotea server code is freely available and other sites have installed their own workgroup servers. The basic annotation capabilities and reply threads described in Sections 3.1-3.4 have been implemented in at least one Annotea client. The user interface of this client, the W3C opensource Amaya editor/browser, is presented in Figure 2. The bookmarks and topics described in Sections 3.5-3.6 have also been implemented in the server side, however, the client user interface is still under development. We have also had some preliminary experimentations in presenting EARL-like accessibility evaluations as annotations.
Many aspects of Annotea, especially the data model and the server implementation, are easily extensible and offer interesting opportunities for future development. The extensibility of the user interface implementation lags behind and while experimenting with various user interfaces we would also like to be able to make the user interface definitions more flexible. For instance, we would like to use metadata based user interface profiles so that so that we can incorporate user-defined RDF schemas in the user interface without requiring changes to the client code.
As of Amaya release 6.2 we still need to code the user interfaces separately for each client. The bookmark user interface is currently high in our priority list, as are enhancements to the user interface that will help the current Annotea users. For instance, it would be nice to be able to use CSS to define some aspects of presentation style. Thanks to volunteers we currently have several Annotea client plug-ins [Annozilla, Snufkin, Bookmarklet] tailored for different browsers. Amaya is our primary development client. To let anybody easily browse the content of the annotations we also would like to have a proxy client that can be used from any Web browser.
Greater flexibility in addressing portions of documents is needed. Our current Amaya implementation relies on XPointer technology. However, XPointer is only specified for XML documents (though our implementation extends this use to HTML documents as well). The definition of the context property was intentionally made broad to support other forms of content identification. For instance, it would be nice to be able to use an SVG outline to define a location in an image or use a time code for a location in video or audio.
Annotea supports a subset of first order logic in limited use, such as the topic hierarchy examples given above. In the future, we would like to be able to add more logic definitions e.g. to permit the user to write rules to select the annotation icon based upon properties of the creator of the annotation, properties of the service in which the annotation is stored, or arbitrary properties of the annotation such as its age.
We also would like to offer more tools for the users to easily define new annotation types with additional properties. This is in part a user interface issue; for example, the task of marking an annotation containing a 'change proposal' as 'completed' might be implemented as the creation of a Reply of a certain type. A type-specific rule could use information in the reply to adjust the presentation style of these 'completed' changes.
Finally, Annotation information could be incorporated into the rankings of search results computed by search engines, raising or lowering the ranking according to rules specified by the user or adding icons to highlight some results.
Annotea is a metadata based annotation infrastructure for sharing annotations on Web documents. It uses standard W3C technologies and can support a broad range of different annotation needs. The generic property mechanism of RDF allows us also to construct ontology-neutral data stores. Applications can use several ontologies simultaneously to describe different aspects of their annotations.
The basic annotation schemas are easy to extend to support many kinds of annotation needs presented in the scenarios in this paper. Also the server is capable of storing the new schemas and responding to many kinds of queries including some limited first-order logic. Currently, the most tedious work is in customizing the user interfaces to support the new schemas. More research is needed to ease the presentation of the metadata, especially new properties from ontologies the application (or user) may not have previously seen.
Annotea is a team effort. This paper is based on and the authors are deeply indebted to the innovative and hard work of Jose Kahan, Eric Prud'hommeaux, and Art Barstow. In addition, Eric Miller, Charles McCathieNevile, Dan Brickley, Martin Duerst and other W3C staff have contributed many ideas to Annotea. Matthew Wilson and Jim Ley have been early adopters and contributed to the work through their own client implementation efforts. Elisa Communications provided funding for a portion of the work.
Partial funding for the development of Annotea was provided by the Defense Advanced Research Projects Agency (DARPA) and Air Force Research Laboratory, Air Force Materiel Command, USAF, under agreement number F30602-00-2-0593.
[Amaya] Amaya Browser/Editor home page. http://www.w3.org/Amaya/
[Annotea 2001] José Kahan, Marja-Riitta Koivunen, Eric Prud'Hommeaux, Ralph R. Swick. Annotea: An Open RDF Infrastructure for Shared Web Annotations, in Proc. of the WWW10 International Conference, Hong Kong, May 2001 (http://www10.org/cdrom/papers/488/index.html).
[Annozilla] Annozilla home page. http://annozilla.mozdev.org/
[Arakne 2002] Niels Olof Bouvin, Polle T. Zellweger, Kaj Grønbæk, Jock D. Mackinlay. Fluid Annotations Through Open Hypermedia: Using And Extending Emerging Web Standards, in Proc. of the WWW2002 International Conference, Honolulu, Hawaii, May 2002 http://www2002.org/CDROM/refereed/656/index.html
[Bookmarklet] Annotea bookmarklet home page. http://www.w3.org/2001/Annotea/Bookmarklet/Annotea-JavaScript.html
[DAML 2001] Frank van Harmelen, Peter F. Patel-Schneider and Ian
Horrocks (eds.). Reference description of
the DAML+OIL (March 2001) ontology markup language, Joint United States /
European Union ad hoc Agent Markup Language Committee
(http://www.daml.org/2001/03/reference.html)
[DCMI 1999] Dublin Core Metadata Initiative, Dublin Core Metadata Element Set, Version 1.1, http://purl.org/dc/documents/rec-dces-19990702.
[EARL 2001] Sean Palmer (ed.). EARL 1.0 Specification, WAI ER WG Note 09 December 2001. http://infomesh.net/2001/earl1.0/
[Haystack 2002] David Huynh, Dennis Quan, Vineet Sinha, and David Karger. The Semantic User Interface Paradigm for Presenting Semi-structured Information. Student Oxygen Workshop 2002.
[KCAP 2001] Marja-Riitta Koivunen, and Ralph Swick. Metadata Based Annotation Infrastructure offers Flexibility and Extensibility for Collaborative Applications and Beyond, in Proc. of the KCAP 2001 workshop on knowledge markup & semantic annotation.
[RDF 1999] Ora Lassila and Ralph R. Swick (eds.). Resource Description
Framework (RDF) Model and Syntax Specification, W3C Recommendation,
February 1999
(http://www.w3.org/TR/1999/REC-rdf-syntax-19990222).
[RDFS 2000] D. Brickley, R.V. Guha (eds.). Resource Description Framework (RDF) Schema Specification 1.0. W3C Candidate Recommendation, 27 March 2000. http://www.w3.org/TR/2000/CR-rdf-schema-20000327.
[Snufkin] Snufkin home page. http://www.jibbering.com/snufkin/
[WAI] Web Accessibility Initiative home page. http://www.w3.org/WAI/
[1] Although AWG might resemble a real W3C group it is used here as an imaginary group.
$Revision: 1.123 $ of $Date: 2002/08/22 13:33:11 $