RDF Query and Rules Framework
This document is intended to provide an understanding of the concepts and issues related to querying semantic web data. Andy Seaborne is working on an taxonomy for recording (and comparing) the results of these queries.
This document has no formal standing in terms of the W3C 'recommendation track' standards process. It is the product of collaborative work in progress by the authors and contributors to www-rdf-rules list.
RDF/XML, N3 and nTriples all provide ways to instantiate directed labeled graphs. A logical way to view the results of parsing such data is that it produces a data structure with a series of statements, each with a predicate, subject, and object. This data structure, henceforth called a graph, provides utility to applications when they have a mechanism for retrieving specific pieces of data and acting upon it.
In most query languages, the data is retrieved by submitting a template subgraph which is matched against a graph. For instance, this query 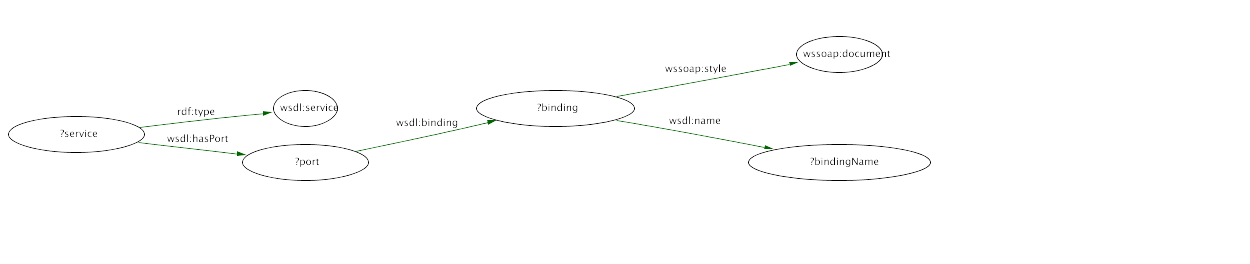 would have one solution in this graph.
would have one solution in this graph. 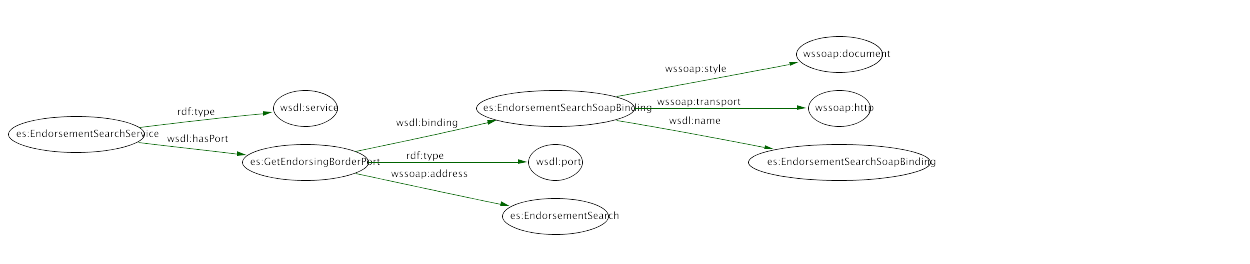 An application could use this query to find a web service that uses a soap document. The es:GetEndorsingBorderPort and es:EndorsementSearchSoapBinding, bound to the variables ?port and ?binding, may be returned to the application so it could initiate a converstaion with es.
An application could use this query to find a web service that uses a soap document. The es:GetEndorsingBorderPort and es:EndorsementSearchSoapBinding, bound to the variables ?port and ?binding, may be returned to the application so it could initiate a converstaion with es.
While RDF query languages vary, many exhibit similar features. The section describes the parameters that describe an RDF query language. For simplicity, imagine that the query or rule is expressed in the following tree:
<LanguageIdentifier>
<Message Characteristics />
Goal:
<Goal characteristics...>
Open Subgraph Query
</Goal>
Result: one of:
<Report characteristics...>
Result Set (variable assignment propositions)
</Report>
or
<Assertion characteristics...>
Bound Graph Assertion
</Assertion>
</LanguageIdentifier>
This tree uses XML-like markup to indicate hierarchy, however, the languages mapped to the resultant taxonomy need not have a similar, or even any, XML representation.
- Scope
- An assertion that that some graph pattern implies another graph pattern is a rule. The rule may have different lifetimes. Likely lifetimes are
- premise
- Assertions, query-definitions (views) or rules will be only perishably kept in the source's knowledgebase, i.e., only for the duration of the session. These may furthur be broken down:
- once
- The rule is applied once and is forgotten even as the rest of the query is performed. For instance, compute the transitive closure of ancestors once and forget the rule.
- query
- The rule is stored and may be applied as furthur terms in the query arrive at preconditions. For instance, compute the transitive closure of ancestors and keep the rule so that each new ancestor assertion will result in the proper transitive closure calculation.
- durable
- The database engine keeps the query or rule around to apply beyond the current transaction. For queries, this would be a subscription and would require some messaging mechanism outside the current transaction.
- Service Capability Requirements
- The requirements for sound and complete inferencing demanded of the service by the requestor. For example, some query/rule languages allow variables in the predicate position and many first order logic systems do not support such rules. In a more constrained example, many relational databases support only a simple graph query with no premises.
- Effort
- time limit
- Spend a prescribed amount of time attempting the query or inference.
- Exhaustive Solution
- A language may be set up to quit searching after the first solution, positive or negative, is found. This characteristic would be more common in backward chaining engines as forward chainers have little extra work to do to report the extra solutions.
- error reporting
- A standardized format for reporting errors. In very versatile languages, this may be analogous to Java exception tree. The W3C XMLP working group has discussed this issue at length when designing SOAP fault codes. Some important faults that may be thrown (following the java exception analogy):
- query [expression @@@] exceeds service capabilities
- Thrown when the service recognizes a request as exceeding its reasoning or assertion capabilities. For example, a client uses a language sends a message with variables in the predicate position and the service is unable to handle such expressions.
- timeout
- user timeout
- User requested a timeout which was exceeded.
- system timeout
- time restriction imposed by service
- ephemoral
- Temporary resource constriant -- try again later.
- policy
- This is a fixed system timeout -- requestor is not encouraged to try again.
- internal error
- Some portion of the service encountered an error that the requestor may not remedy. This could include file corruption or network errors when trying to reach federated data sources.
The goal represents a subgraph to be matched.
- graph or arc
- Some languages express a single arc, others an open subgraph. No observed single arc languages support variables @@ still true? @@. This leaves them unable to answer the specific query
represents(?x ?x) "What lawyers represent themselves?" but instead the more general question represents(?x ?y) "What lawyers represent anybody?".
- Arbitrary Graph
- Some languagesare good for querying an arbitrary RDF graph while others are tailored to query, for instance, transitive properties from RDF schema.
A has friend B and B works for C and C live next to A
- Variable Predicate
- Can a variable appear in the predicate position. For example, the following rule requires a variable predicate:
rule r2: transitiveProp(?tp) ^ ?tp(a, b) ^ ?tp(b, c) => ?tp(a, c)
- Literal Evaluations
- Funcs like <, >, substr.
X works for BigCo and X was hired before 1990
- Disjunction
- Test if a or b is true.
X works and night and (X in process control || X in system maintenance)"
This set is the union of the results from the two queries
X works at night and X in process control
and
X works at night and X in system maintenance
- Node Selection by Pattern
- Nodes may be selected by patterns such as wildcards or regular expressions. This mimics the functionality of aboutEachPrefix.
- optional arcs
- Don't eliminate solutions where an arc doesn't bind, similar to SQL's OUTER JOIN.
tell me Bob's email address and, if you know it, his snailmail address
- safe negation
- A query has safe negation when the negated clause has no variables in it. A query like
X works for bigCo and X is not in shipping
can be made safe by evaluating the works for clause and getting bindings for X before evaluating the
X is not in shipping
clause.
- stratified negation
- @@ check this. @@ Queries are not stratified if selection of some graph implies a clause that was negated in the query. eg
select all X that are not selected by this query
is not stratified. In practice, unstratifed queries will only be possible if the query can reference its own results. For rules, if the implication sometimes affects a negated clause in the query, the rule is not stratifed.
- negation as failure
- The goal is met if the system fails to prove a proposition, or, in non-inferencing triple stores, fails to contain that proposition. When implemented in relational databases, this is an aggregate function that returns true if there were no solutions.
who are all the people who manage somebody but have no manager themselves?
- Bound
- (must, may, don't) bind. may and don't bind allow for results where the proof is from a rule and not a ground fact.
- Data Source Identification
- The results of a query are likely to be interpreted differently depending on the source of the data. Data Source Identification states whether the query language provides the sources of the solutions found.
- Report Style
- How the service reports the results of a query to the requestor. Queries resulting in multiple solutions
The report may include bindings or assertions or both.
- Bindings
- A matrix of variable bindings where the columns represent the (requested) variables and the rows represent the solutions to the query.
- Solution Propositions
- An array of graphs where each graph represents a solution to the query.
- Aggregate
- All relevent assertions are stated in a single, monolithic graph.
- (maximum) number of rows.
- How many solution sets (propositions) are returned to the requestor.
- cursor
- Whether the reporting mechanism offers cursors for incremental access to a large data set without transfering the whole set at once. Issue: such a data set may be rendered inconsistent by data updates or the service may provide a locking or caching mechanism to protect the integrity of the queued data set.
- --------------------
- Propositions
- Solutions are structurally divided.
- Table
- Results returned in the form of a table (relation) such as one would expect from SQL. Characteristics of table answers include:
- Selected
- List of variables for which to return the bindings.
port and bindingName are used in the following examples.
- (maximum) number of rows.
- How many solution sets (propositions) are returned to the requestor.
- cursor
- Whether the reporting mechanism offers cursors for incremental access to a large data set without transfering the whole set at once. Such a data set may be rendered inconsistent by data updates or the service may provide a locking or caching mechanism to protect the integrity of the queued data set.
- Graph Assertions
- Set of statements asserted as a consequence of a goal match.
- proofs
- Proofs are similar to a subgraph assertion except that it includes all the rules and ground facts that led to the arcs in the subgraph assertion. For example given:
rule r1: ancestorOf(a, b) ^ ancestorOf(b, c) => ancestorOf(a, c)
ground fact gf1: ancestorOf(dad, son)
ground fact gf2: ancestorOf(gramps, dad)
ground fact gf3: playsInstrument(son, tuba)
will result in the derived fact
derived fact df1: ancestorOf(gramps, son)
The query for all ?x,?a where playsInstrument(?x, tuba) ^ ancestorOf(?a, ?x)
would result in the table solution:
?x ?a subgraph proof
son dad gf1, gf3 gf1, gf3
son gramps df1, gf3 gf1, gf2, r1, df1, gf3
For a full "proof", the sources for the ground facts and rules would have to be identified.
- Exhaustive Solution First Next
- An engine capable of performing an Exhaustive Solution may return a handle to the caller so that the caller may ask repeatedly for the next solution. Again, this is more likely in backward chaining engines.
Separate from the Goal graph, the query/rule may have a defined model.
- binary relations (RDF)
- The RDF-modeled query/rule languages may encode the Goal graph in different ways:
- application-specific reification
- RDF reification is a mechanism for "hiding" an assertion by asserting that the assertion exists and naming its component predicate, subject and object.
- direct inclusion
- @@@ dangerous (may answer its own query). don't know that anyone does this.
- n-ary realations (datalog)
- other or undefined
The abstract syntax must be serialized in order to be passed to a query/rule handler.
- XML
- RDF
- The query is expressed as a graph and is encoded in RDFXML.
- non-RDF
- The query is encoded in an XML schema that does not correspond to a conventional way to represent RDF triples
- ascii
- N3
- cwm
- SQL-ish
- Squish, Inkling
- History
- A particularly challenging modeling problem is the representation of history in the datasource. The web is frequently viewed as set of documents representing the current represented status. Applications requiring a history provide the data in the context of this current status. For instance, an issue tracking system will usually provide a view with the current status of an issue and another view with the history of states that the issue has gone through. Similar approaches provide a document history by giving access to the history in a revision control system. With RDF, the representation of history becomes more tractable as the information is generally more compact and atomic. The history parameter describes whether a query language (and probably the underlying data storage facility) provide access to the history of data that has been exposed to the system.
- model
- A query languages may have a defined mapping to an RDF DLG. These languages may be encoded in RDF languages like RDF, N3, NTriples. See model.
Most current RDF query languages are defined by a single implementation. Query language definitions outside of the implementation documentation may have different characteristics than the implementation. For instance, some features may not yet be implemented or may be implemented inefficiently. Two handy dimensions are soundness and completeness.
- soundness
- The reliability of the service to produce only facts which are "true", ie, that the logic of the ground facts, rules, and grounds facts would support.
- completeness
- The thoroughness with which the service finds all "true" facts.
Soundness and completeness are considered with respect to a particular logic feature. For instance, the rules and facts
rule r2: transitiveProp(?tp) ^ ?tp(a, b) ^ ?tp(b, c) => ?tp(a, c)
ground fact gf1: ancestorOf(dad, son)
ground fact gf2: ancestorOf(gramps, dad)
ground fact gf4: transitiveProp(ancestorOf)
would lead one to beleive
derived fact df1: ancestorOf(gramps, son)
A service that was not complete with respect to rules with variable predicates would fail to arrive at this conclusion, and, would probably fail to parse ?tp(a, b).
Additional characteristics:
- max number of queries
- How many queries a requestor may make in a given session or period of time. This is "no limit" for all of the services surveyed.
Following is a rough pass at describing interactions between the above taxonomies and other relevent taxonomies. This taxonomy has not been expressed as a set of RDF Statements and Properties so some ambiguity exists between proerties and the classes that are the domains of thise properties.
Minor taxonomy mismatch: individual vs. group of individuals.
Several core architectural issues relating to queries are yet unspecified. These are being addressed int he RDF Core and the Joint Committee forums.
bNodes, also called anonymous nodes, are nodes that were imported into a graph without a fixed identity. These nodes need identification within a data store or in memory database as they may be used in more than one arc. For instance, 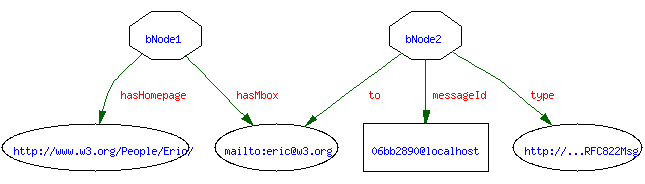 has two bNodes representing objects with distinct properties. According to RDF Core, bNodes are interpreted as existential variables. In a query context, this could allow the subject in the above DQL query snippet to be expressed as an anonymous node.
has two bNodes representing objects with distinct properties. According to RDF Core, bNodes are interpreted as existential variables. In a query context, this could allow the subject in the above DQL query snippet to be expressed as an anonymous node.
(See the associated RDF Core issue.)
- none at present