Deductive Triple Stores
This is a working draft, written and maintained by Sandro Hawke.
Feedback welcome in private at sandro@w3.org
or public at www-rdf-logic@w3.org.
To Do (not in a specific place later)
- @@Figure out how to read/write/be-notified-of annotations to this
- @@ How to read the API spec -- in order / reverse order, add "used
by" links
- @@Consider: how do implement with Tim's "context" approach with this API?
1. Purpose
This document takes a programmer's approach to defining how
knowledge and logic might be handled on the Semantic Web. It attempts to
avoid philosophy and traditional AI terminology, for better or worse,
and language syntax disagreements by just specifying the behavior of
software at an API. We hope this approach will make Semantic Web
logic sufficiently clear to a wide range of implementors and
users.
2. Data Model
Our data model is simple and abstract. It is similar to the
RDF Model but uses terminology more familiar to programmers and
omits higher-level abstractions for types and collections (which we
re-introduce later in a different form).
A deductive triple store manages a set of simple logical assertions
which can be used to represent almost any knowledge. More
specifically:
- Objects:
-
The things we are talking about.
These are the things themselves, like people,
cities, web pages. We can also talk about more abstract
objects such as particular relationships or infinite sets.
- Identifiers:
-
A kind of object in a language (such as a word or symbol) used to
identify objects which are not part of the language (like people).
- Symbols:
-
Internal identifiers, used in the Core API (detailed below).
Symbols can only be compared and copied.
- Global Names (URIs):
-
Character strings used to identify objects in a wider context.
Generally following the URI-Reference syntax to facilitate
management, although this practice is not mandated by this API.
- Property Statements:
-
A kind of assertion of fact relating
three objects in the roles of "subject", "property", and "value".
In English, property statements can be read like "Dan has a residence
in Texas", where there terms "Dan", "residence", and "Texas" identify
the subject, property, and value objects (respectively).
- Triples:
-
Objects composed of three objects in distinct positions or roles.
In this context, we usually mean a property statement, but perhaps
without semantics attached to the roles. Specifically, the
Core API keeps the roles separate, but treats them the same.
- Knowledge Base
-
A knowledge base is a set of property statements. Software for
managing this kind of knowledge base is called a "triple store",
because it stores three-part statements.
- Languages
-
A knowledge base may be serialized as a character sequence,
transmitted or stored, then deserialized using many different
languages, such as RDF Basic
Syntax or any trivial triple
syntax.
In general, we call any mapping between a character sequence and
a set of property statements a "semantic web language."
- Vocabulary:
-
A set of global names, mapped to objects in manner understood
by all parties to a communication.
3. API
A deductive triple store (DTS) is an entity which remembers triples for
you, can generate new ones under certain conditions through a process we call
deduction or inference, and can answer queries about the
combined given and inferred triples.
We separate our standard DTS into several distinct parts:
- The Core, which handles triple statements, deduction rules, and queries
in native (platform and implementation dependent) data structures
- The Codec, which converts between native data structures and a standard
triple representations of the information in those structures
- Serialization generators and parsers, which convert sets of triples into
standard byte or character sequences, such as RDF.
- @@@@ a manager, for things like theorems and negation and security ?
The interfaces look something like this. @@@@ It's rather tricky to
see where apps and language interface units should sit; the
codec+feedback units give you some flexibility, but how do you avoid
nastiness?
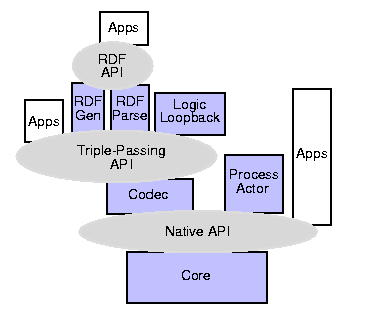
A diagram of the Core, showing the API (at the top) and how it relates
to internal components.
The API is presented here in an abstract pseudo-code-like
notation.
There should be C++ and Python versions for reference, too, at
least. Probably also C, Java, and Perl.
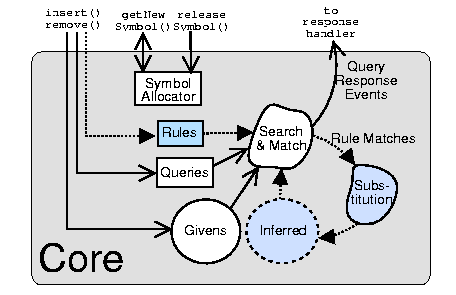
3.1. Core API (Abstract Version)
In general, the core stores sets of Givens, Queries, and Rules for the
application. When run, the core tries to match up the queries with
some of the givens or with possible output from the rules; whenever it
finds a proper match, it sends a QueryResponseEvent with the details.
Without any rules, this is simply a triple-store with an
asynchronous interface (which can be wrapped with a synchronous one).
With rules, it is a fully programmable processor (equivalent to a
non-deterministic Turing machine) with an interface designed for clear
distributed semantics instead of efficient operation.
3.1.1 Classes Passed Down To Core
- class Statement
- A simple record structure of three elements. Structure equality
should be based on element equality.
- Symbol subject
- Symbol property
- Symbol value
- class Budget
- A general structure parameterizing the computational effort
which should be expended on Rule and Query procession. Needs
to be general enough for cross-platform use but specific
enough to support real use.
- Number maxProcessorSeconds
- Number maxRealSeconds
- Number maxBytes
- Integer priority
- All queries with the highest priority will be worked on before
any at a lower priority
- Number processingShares
- Among queries at the same priority, processing efforts will be
divided roughly in proportion to the number of
procssingShares
Should perhaps divided into a class hierarchy with
QueryBudget and RunBudget having some different qualities. In a
QueryBudget the priority is the min-runnable
priority, and pShares is meaningless.
- class Callback
- An entry point in the Application, called as an event handler for
QueryResponseEvents
- handleEvent(Core, Query, Event)
- During execution all core methods except the destructor and
run() may be called
- class Query
- Specifies a pattern of statements of interest.
- StatementList pattern
- SymbolList vars
- Callback eventHandler
- QueryBudget budget
A Query is matched by given and deduced statements which
are equal to each statement
in pattern, after each occurance of
any symbol in vars is replaced by some symbol.
- class Rule
- Represents permission to deduce new Statements.
- StatementList ifs
- StatementList thens
- SymbolList univars
- SymbolToSymbolMap depvars
The statements in thens may all be deduced
if the statements in ifs are all matched
as a Query pattern.
If any symbols in the domain (keys) of
depvars are present, the deduced and matched
statements should have those symbols replaced by other
symbols: the replacement symbols depend on the replacements
for the univars which are mapped-to; for each unique set of
these replacement symbols, the depvar should be replaced with
a new symbol.
A set of these rules is logically equivalent to a formula of
first-order logic. These rules may be considered as logical
formulae in implicative normal form, where univerally quantified
terms are univars and Skolem functions are
depvars (@@@@ provide code to convert
between these forms.)
3.1.2 Classes Passed Up From Core
There are all record-style classes, with no operations beyond data access
required.
- class BoundRule
- Represents a Rule with its variables all bound for replacement with
some (probably different) symbols.
- Rule rule
- The Rule (or a pointer to it) used in this step
- SymbolToSymbolMap bindings
- Maps each Symbol which is present in rule.univars or as a key in
rule.depvars to a Symbol with which it should be considered
replaced.
- class Proof
- BoundRuleList steps
- A list of bound rules in an order which can be be directly verified
by successive rule applications from some given statements or
already-generated infered statements.
- class QueryResponseEvent
- Created when the Core discovers something relevant about a Query (such
as a new match) for passing to the Application
- Enum {Insert,Remove,BudgetExceeded} type
- SymbolList varBoundTos
- Proof proof
3.1.3 DTS Core Interface
- constructor(String specificationURI)
- Create the engine and its empty knowledge base. We provide the URI of
this document (which specifies API behavior), so that multiple versions (with different behaviors) can
potentially use the same API.
- destructor
- Deallocate the engine, discarding its knowledge base.
- getNewSymbol() returns Symbol
- Returns a new or unused and released Symbol
- releaseSymbol(Symbol)
- Tells the engine that the given Symbol may be reused. Any Statements
using only released Symbols may be garbage collected inside the engine.
In some environments, the engine may be able to keep a weak reference to
the Symbol and let the environements garbage scanner notify it of
Symbols not used by the application, eliminating the need for this
method.
- insertGiven(Statement) returns Boolean
- Adds the statement to the "givens" in the knowledge base. Additions of
Statements matching currently held Statements on a Symbol-for-Symbol
basis are ignored (but cause a return value of false, else true)
- removeGiven(Statement) returns Boolean
- Removes the statement (as stored with the given Symbols), if present.
Returns true if it was present.
- insertRule(Rule) returns Boolean
- Allows the Core to perform the specified inferences
- removeRule(Rule) returns Boolean
- Instructs the Core to stop performing the specified inference and
remove any/all Statements actually inferred using it (and notify Query
event handlers, as appropriate). It is an error to remove a Rule not
present. If two different rules could be used to infer a statement, and
the one that actually was used is removed, the inferred statement may be
removed for a time until the other path is found.
- insertQuery(Query) returns Boolean
- Adds the Query to the engine's currently set of active queries. All
queries remain active until removed, although only the ones equal to the
priority of the highest-priority one are actively processed.
The query's event handler will be called with insert
events for each query match which is found, and remove
events for each past match which is lost due to givens being
removed or the
rules which generated inferred statements being removed. The Core may provide remove events for
matches which it has not yet told the handler.
Until the return from the handler, engine operations are suspended
even in multi-threaded environments. If you want the engine to
proceed, the handler should pass its information to another thread and
return.
Queries will often get duplicate events, so it is common to have an
initial response point which stores result values and only passes on
real changes.
Note that queries will not return any released symbols.
- removeQuery(Query) returns Boolean
- Removes the query from the the engine's set of queries.
- run(Budget totalBudget)
- Lets the engine begin trying to satify any and all queries, subject to
priority and Budget constraints. Will continue until stop() is called,
no more query work can possibly be done, or the budget it exceeded.
- stop(Boolean keepState)
- Called from inside an event handler, makes the run() method return.
If keepState is true, then the engine should not abandon its search
state, and the next call to run() should proceed from where it left off.
This should have no material effect on results (since event duplication
by an engine is permitted), so the decision to implement it is based on
efficiency vs. program complexity.
Notes:
- Without any calls to insertRule(), an engine is just a triple
store.
- The event model for queries should properly support replication and
distribution.
- The SQL "cursor" approach to queries can be implemented on top of this
interface with threads or continuations, or @@maybe using keepState=true
and shifting priorities.
- Different approaches to implementation will have radically different
performance and implementation complexity, with the scale ranging from
too-slow-to-be-useful to decades-of-algorithm-research. We believe there
are some useful points in the middle.
3.2. Codec API (Abstract Version)
- Constructor (Core, Basis)
- encode(native_object source, symbol dest)
- Enters into the core knowledge base all the information contained in
the source native object, as the value of the symbol dest.
This would need to be written as a family of functions like
encode_int(int, Symbol) in a language like C without overloading or
run-time type information.
- decode(symbol source, native_object dest)
3.3 Other API
@@ get engine state symbol and/or engine symbol
@@ URI connections
@@ LoopBack Behavior!
@@ How to handle Literals They don't need to be understood; they
can be described logically (eg peano arithmetic) -- but it's
probably good to have them short-cut understood.
4. Standard Encoding
@@ Vocabulary for Triple version of this API
5. Experiences
5.1 Roads Prototypes
Starting with proto4 in March 1997, Sandro has been sucessively attempting
create a practical implementation of something very much like this. Proto8
(Oct 1998) was a java version with verifier and naive forward chaining (using
tuples, not triples). Proto9 (Nov 1998) added a subsystem for encoding and
decoding java objects. Proto10 (Feb 1999) moved to triples, but the approach
to inference was much more complicated. Proto13 (Oct 1999) had a backward
chainer. Proto16 (Jul 2000) was written in C++ and included a backward
chainer using several optimizations, but currently lacks a decoder and the
remove_ operations
@@@@ downloads of APIs, implementations, and test suites!
6. Applications
@@ write something about theoretical and practical (performance) limitations
of this approach! Point out techniques for translating from the
rule domain to the native execution domain to allow normal-speed operation.
@@ Talk about applications: UI for browsing proofs,
query-for-next-action loops. Providing big sets of rules
and code which does something they would do -- either from a
trusted source or with a proof.
@@ Talk about theorem. An app can make a core to verify one, then add it
as a rule to another core