Aggregate Roll
Present:
Cisco: Raj Nair
Ericsson: Nilo Mitra
Fujitsu Limited: Kazunori Iwasa
Hewlett Packard: Stuart Williams (scribe)
IBM: Dug Davis
IBM: John Ibbotson
IBM: David Fallside (chair)
Idokorro Mobile (Planetfred): Mark Baker
IONA Technologies: Oisin Hurley
Lotus Development: Noah Mendelsohn
Macromedia: Glen Daniels
Microsoft Corporation: Henrik Nielsen
Microsoft Corporation: Paul Cotton
Oracle: Jeff Mischkinsky
Rogue Wave: Murali Janakiraman
SAP AG: Gerd Hoelzing
SAP AG: Volker Wiechers
Sun Microsystems: Chris Ferris
Sun Microsystems: Marc Hadley
Systinet (IDOOX): Jacek Kopecky
Present (partial):
Active Data Exchange: Richard Martin
Mitre: Paul Denning
Mitre: Marwan Sabbouh
Oracle: Anish Karmarkar
W3C: Hugo Haas
Present (remote):
Canon: Jean-Jacques Moreau
Canon: Herve Ruellan
DevelopMentor: Martin Gudgin
Intel: Highland Mountain
Software AG: Michael Champion
W3C: Yves Lafon
Excused:
Active Data Exchange: Shane Sesta
Cisco: Krishna Sankar
DevelopMentor: Don Box
Fujitsu Limited: Masahiko Narita
Intel: Brad Lund
IONA Technologies: Eric Newcomer
Macromedia: Simeon Simeonov
Rogue Wave: Patrick Thompson
Software AG: Dietmar Gaertner
Systinet (IDOOX): Miroslav Simek
Regrets:
Akamai Technologies: Mark Nottingham
AT&T: Mark Jones
BEA Systems: Jags Ramnaryan
BEA Systems: David Orchard
Compaq: Yin-Leng Husband
DaimlerChrysler R. & Tech: Mario Jeckle
Data Research Associates: Mark Needleman
Matsushita Electric: Ryuji Inoue
Philips Research: Yasser alSafadi
Philips Research: Amr Yassin
Tibco: Frank DeRose
Unisys: Lynne Thompson
WebMethods: Asir Vedamuthu
Xerox: Ugo Corda
Absent:
AT&T: Michah Lerner
Compaq: Kevin Perkins
DaimlerChrysler R. & Tech: Andreas Riegg
Interwoven: Ron Daniel
Interwoven: Mark Hale
Library of Congress: Ray Denenberg
Library of Congress: Rich Greenfield
Martsoft: Jin Yu
Netscape: Ray Whitmer
Netscape: Vidur Apparao
Novell: Winston Bumpus
Novell: Scott Isaacson
Tibco: Don Mullen
Unisys: Nick Smilonich
WebMethods: Camilo Arbelaez
09:00 Introductions:
09:10 Scribe: Stuart volunteers.
Agenda Review:
DF: Walks through agenda
09:15 Schedule (discussion preview)
DF: Previously expected to go from this meeting to last-call within a week. That won't happen. There are a bunch of documents that need to be completed. We aren't going to manage that in a couple of days
AOB Call:
None from Burlington;
None from Rennes
None from Zakim audio
09:20 Approval of minutes from Telcon of 21st Novembers 2001
DF: Issues/corrections to minutes?
Silence
DF: Approved as posted.
Action Items:
MB: Issue 54 resolution text submitted. Done!
HFN: Rewrite of R309... still pending
MB: Issue 40 resolution text. Henrik had offlist concern with 2nd paragraph. Minor concern...
DF: Do we have final text for 40. Please coordinate (MB, Marwan, HFN?) to finalise this text.
HH: Yves reports that he has completed AI with Winston. Mail sent, no reply... mark pending.
SKW: Isse 32 resolution text... done.
MH: Issue 172 text... done
SKW: Issue 146 text... done
Gudge: Issue 130 text... pending
Editors: Fault dot notation removal... pending
HFN: New issue on fault codes... pending.
PC: Question re resolution of issues related to Base64 (i97) and possible dependancy on XML Schema.
DF: This is an ETF flagged issue.
09:30 Schedule:
DF: Couple of slides... apologies to remote particpants for not being able to present these remotely. Will make best efforts to describe.
DF: Scenario 1: Previous schedule...
[Ref David's slides] scenario2 scenario3
New schedule:
LC WD early Feb 2002
PR WD late Apr
REC Mid July
Assumes we resolve issues and test cases by end of Jan.. the LC end Jan/early Feb.
One of the things that makes this scenario less attractive is the 'hanging' F2F at the end of Feb. Not great wrt schedule.
We have spoken about F2F at the end of April for F2F prior to PR.
DF: Scenario 2 (Green triangle).
LC WD end Feb (take advantage of Cannes F2F prior to going LC)
PR WD end May
REC mid Aug.
NM: Quiet period in August?
DF/PC: Need to assume publication will occur more slowly in August.
MB: What happened to CR?
DF: Due to widespread implementation W3C has advised that we can dispense with CR period. The LC period is slightly extended.
RM: Some question of combining with a Web Services activity.... any impact?
DF: Don't think this will impact us.
CFerris: What would it take to get some commitment to doubling up on the number of telcons?
DF: Given TBTF and ETF commitments... I think that it is difficult to schedule.
NM: How many folks have read both the specs from cover to cover recently...?
No response.
NM: I think that there are a bunch of things that we need to address that are not evident in the issues list. Some things need serious wordsmithing... eg. issue of defaulted attributes. If we got to LC by early to mid-Jan we should be substantially done. Propose, with some nervousness, that we go for second option.
HFN: ...so how do we do this?
NM: Basically have to encourage everybody to read the specs. Generate review commentary for a team including the editors to consolidate, and present back to the WG to ensure that all issues are captured...
CF:
NM: Editorial team needs to get to comfort level that the document 'reads well'....
DF: Can see this forming as an action to the editors to propose back to the group how to achieve this...
MH: Partially this is due to our resolution text and the reluctance of the editors to massage carefully worded text and not destroy meaning.
Jeff: back to discussion of schedule... what if even the green triangles don't work out... what's the fallback?
DF: We can't go to last call with open issues. It is under our control what we accept as issues. We could impose a timelimit on when we are open to accept issues (W3C may have an issue with us doing that). What happens if we're not done... theres the hard approach which is that we just don't let it go past that mark...
HFN: Concern that we are not as good at resolving issues as we might be. Encourage that we do more on the issues on email so that we can be more efficient on email. "How many issues have I helped resolve this week"
NM: ...so reality is that we will get push back when we go to LC. Want to go for good 80/20 cut on Issue resolution. We don't want issues that are not adequately resolved will bite at a possibly inconvenient time.
PaulC: Hard for a WG to push for a change in status without a F2F. So support 2nd option. Need to ensure that the LC draft is available well ahead of that F2F. Wanted to publically put on the table frustration with issues going undiscussed on email. So when it comes to crunch time you have make sure that you've done due diligence on to the discussion ahead of the telcons/meeting.
Dug: Another WD for public viewing?
DF: When...?
DF: I'm assuming that we will prepare a new draft after this meeting... our heartbeat (due 2nd Jan). Something substantive... needed for heartbeat.
Anish: How does new schedule affect new charter proposal?
DF: This is currently SOAP without attachments. Schedule is based on what we already have on our plate. Still intent to recharter inclusive of SwA... still a chair's todo.
PaulC: Point of Information: There are 18 substantial issues that none of the TF's own. Suggest that we assign all issues to bodies or groups of bodies.
DF: These substantive issues are on the agenda for discussion...
PC: Clustering...?
DF: There is some clustering.....
PC: So this is about upping the meeting/resolution rate. The ETF will be done in a couple of weeks and more people may become available.
CF: We have had a recent tendancy to close one issue and generate 3 more...
DF: Need to be careful about that. eg. Resolution of 135 did identify that there were two different issues.
NM: The angle to drill on Paul's concern is more parallelism. We've had some pretty chunk TFs. I think that we can do better with smaller 'TF'lets working some of the issues.
DF: Just to further address the parallelism and assignment... went through entire list checking on activity and assignment. If they are not on the agenda, they are 6 postponed and ... 6 against AM and some in a catch bucket. Believe has done due diligence on the entire list.
DF: Suggest that editors take an action to proposal on how to figure out a plan for how to achieve a consistent narrative.
PC: Would like to encourage that we assign two people to read over the entire spec.
NM: Why not very one...
PC: Well we need to have someone to take responsibility.
DF: Ref charter... participation is expected to consume at least 1 day per week of each members time... contribution is expected/required. Returning to the point that Paul/Noah raised... should we assign at least two of the editors to read thorough entire spec.
JI: Picking up on the point from Noah/Paul it would be good to include a none editor. John volunteer's.
Action: JI to read through Part 0, 1 and 2 and generate
Dug: Need to set a date by which the group has fully reviewed the spec.
DF: There were some question marks on the timeline. DF will huddle with editors to clarify the timeline.
..: Good to have a date for a stable review copy.
NM: Two sets of reviews... the pieces that we believe are near final and another capturing those pieces that we are much less certain about.
DF: Commits to clarif schedule by Thursday. Want to keep us on track for this meeting.
10:25 Break
11:00 Review and Publication
DF: We have a number of documents. We need to figure out what to do with a bunch of these.
DF: Oisin can you talk about the test case document?
OH: It's looking more complete... I could perhaps do some review and give a summary before the end of the meeting.
DF: I was expecting Hugo... but...
YL: Hugo has some problem that he has to resolve today... hopeful for Thursday.
DF: Parts 1 and 2... part of the review of the spec is contained within our issues list. We've had some indication from Noah, that there are some other issues... any thing else?
DF: Get the status of the Part 1/2 documents from the editors. Saw Marc Hadley's response:
Part 1/Part 2 Editorial Issue Review:
i145 still outstanding but possibly addressed by resolution of 10
NM: Would find it helpful to have a summary of the technical resolution.
CF: i10 is about PI's and XML Decl.
NM: The crux of the issue seems to be that the means by which an Infoset is transferred is binding specific. We're infoset based so we need an infoset based answer.
DF: Volunteer to address the resoultion of Issue 10 and Issue 145.
ACTION ITEM to Marc Hadley:
i151 Defintion of a SOAP block.
HFN: ...just to be clear we are just reviewing the status here... we're not trying to resolve them right now...
DF: I want to check on the status of each of these issues. I think it is reasonable for folks to see the proposed/actual changes applied to the spec.
Some discussion of the typing of SOAP blocks... element qnames for top level blocks denote block type.
i152... done
NM: Suggest a the addition of a reference to the SOAP processing model. The relevant sections do not declare themselves to be the "SOAP Processing Model"
ACTION: Editors to consider addition of such a reference.
i156... done
i158... wording amendment... done.
NM: Interaction between two sentences that require some further work through addition of the word 'targetted'.
ACTION editors to revisit wording of these sentences to remove the interaction (ref Noah).
i47 Assigned to ETF, not done, candidate text to dist-app, awaiting a response.
i117, i125 ????
i162 change to BNF... done. Need a reference to BNF.
i55... pending
i10... XML Decl in whole messages. Dup of 145?
NM: This uncovers that we need to say something in adjuncts about the relationship between infosets and serialised XML and that is explicit about the conventions used in the examples.
CF: Rationale behind excluding DTD productions/PIs etc. is to get to interop...?
NM: I believe that PIs, Internal DTD subsets et. al are included Infoset.
CF:...???
NM: SOAP messages are formally Infosets and in all our examples we present serialisations, not infosets...
HFN: Just at a sentence to the conventions.
ACTION editors: develop a text to describe these conventions.
....
i110: Normative/Non-normative granularity.... and conventions... not done
i119: Versioning example... done... added example in Appendix A returning multiple version numbers...
i120: Schema type changes ur-type to anyType... done...
i125: SOAP acronym... done... text added that SOAP is not an acronymn...
i143: pending
i147: closed... references from part 1 to part 2. Removing enumeration of part 2 contents from within part 1.
i148: ...done.
i149: Goals text... done...
i150: Section 1.3 wording... done.... infoset style wording adopted.
i153: pending....
i157: Wording amendment... done.
MH: has a list of issue resolutions that have been applied to the spec...
DF: Change log in the spec should be enough. If folks in reviewing the specs, editorial etc... those should be sent in to xml-dist-app... there was a posting a couple of days ago... we need to look through these.
HFN: From the point of view of Issues list its easier to have an email per issue.
ACTION: Issue list maintainers to bring issues list upto date with current resolutions.
DF: Question of what to publish as our next WD. Do we just pub what we have now or do we need to raise the bar? Eg. there are some more issues that have been resolved but not applied to the spec. Is there something that we want to get in:
MH: XML Base support, i48 on data model (needs agreed text).
SKW: What about material from TBTF?
DF: So critical pieces seem like TBTF, XMLBase, ETF....
NM:
MH: Urge some caution in introducing TBTF introduction in Part 1 without accompanying pieces for Part 2. Urge consistency between presentation of bindings in parts 1 and 2.
DF: Didn't quite get the circularity concern.
NM: ... really a sense that I'd be happy if you asked this question again mid-Thursday.
DF: I'm interested in establish a criteria... what if we can agree on the TBTF materials...
HFN: Agree with Marc that it 'would be nice' to have consistency between P1 and P2. If we have to choose I would prefer to have a draft made available ahead of the holidays.
CF: Perhaps we can simply insert a note indicating that we are aware of the inconsistencies. Isn't that enough, and set expectation for the next WD.
DF: Short circuit question... if we did nothing else that changed the content of the spec... would you be happy to put the current draft (editors copy) as the next WD.
MH: Yes...
DF: ...so anything else that you can get done is 'gravy on the turkey!'
11:55 Part 0:
DF: Nilo, you have requested a formal review of the primer...
Nilo: Used completely new examples. Previous version started with concepts, concerns that there need to be a gentle ramp up. Much more needs to be done in the area of encodings and intermediaies.
Marwan:
NM: Once again there's the infoset question... for most users don't be concerned about the difference.
CF: Full treatment of the binding framework.
DF: Need to make sure that concepts are introduced before they are used....
PaulD: References to the Usage scenarios....
DF: I think that's a long standing issue....
JI: need to establish what the role of the Usage scenario documents.
NM: Explaination of the .../next behaviour. Need a simple way of discussing this...
SKW: Possible question of taste... John Doe usage.
DF: URL usages issues... mycompany.com etc. use example.com and example.org.
SKW: Might be useful to say more about the rationale for choosing to put information in header or body blocks.
Section 3:
OH: Was a little surprised to see references to SMTP binding.
Nilo: I do point out that this is not intended to present a normative SMTP binding... this is just an example.
JK: Suggest renaming to SMTP to email binding....
DF: Question... apparent discomfort over SMTP binding. Do we need to make this name change in order to publish as a working draft.
Marwan: I would prefer to stick with SMTP. Don't understand why more vague binding to email would be better.
JK: Well there are a bunch of other protocols involved in transferring email.
HFN: Could say that its and RFC822 binding... don't need to go into the intricate details of that mail protocols that we use.
NM: I hear Nilo agree to the crux of what it takes to publish this. Would rather head down the road of making it clear how sketchy this is. Suggest that second (SMTP) is merely a sketch of how other protocols might be used...
Nilo: Also indicate that there is a bunch of infrastructure pieces....
Marwan: All you need is SMTP....
JK: ... but the description does not say anything about the SMTP commands... HELO, etc...
CF: Re: Section 1 point... we need to address this in terms of the binding framework, possibly with a single feature (eg. simple authentiation) rather than picking on a particular protocol. ie. show how to use the framework.
DF: ...Jacek... there have been a number of framing caveats suggested... would these be ok.
JK: I'd just like to see this renamed to email.
Marwan: (to Jacek) I now understand your concern
ACTION: Jacek, Nilo, joint action to develop mutually agreeable text for SMTP/email binding presentation.
Nilo: On section ?? on alternative encodings...
....(missed discussion).
JeanJacques: Do we have to show SOAP version transition in the Primer... should section 5.2 be in the primer.
Nilo: Thought that a useful think to do was to include changes between 1.1 to 1.2 in section 5.1
Nilo: Section 5.2 was added because it had been asked for during a telcon.
JJM: Assumption is that the main audience for the primer will be new to SOAP...
DF: So... what is your proposal (to JJM).
JJM: One proposal is to remove section 5 from primer.
MH: There's a related question about change logs in the WDs propagating into the final specs...
....
JI: ... so there is the question of the purpose of the primer... if the audience are new to SOAP then section 5.2 is necessary for those people.
DF: Strawpoll on removing section 5 from primer.
NM: Would the way to do this be to separately publish a W3C Note describing the 1.1->1.2 changes that can be referenced from the spec and the primer. Is the administrative burden too... much?
Proposal: Take 5.2 and 5.1 and publish then as a non-normative W3C Note describing 1.1->1.2 changes. In the spec make non-normative reference to the said note.
DF: Can we leave the primer as a temporary home for this material?
CF: I think it makes some sense to move this material to an earlier point in the spec. We perhaps want to telegraph that much of SOAP 1.2 is not so radically different to SOAP 1.1.
DF: Noah's proposal... general consent.
DF: Foreshadow change part?.... general consent....
DF: With those changes in place do we want to promote the Primer to WD...?
General consent... Boston, Renes, Zakim all yes.
12:30 Usage Scenarios:
DF: Comments on Usage Scenarios...
JI: Not received comments... would be useful to discuss the role of the documents. The usage scenarios arise from the requirements. Is this a due diligence document or should it be promoted as stand alone document for wider consumption. Own view is the fromer.
RM: Are you thinking of merging the Usage Scenarios and the Primer.
JI: That was discussed. Merging the two would change radically the style of the document.
JK: Could the usage scenarios become an appendix to the primer.
Nilo: I had hoped to take a few key examples from the Usage scenarios to strengthen the primer. Don't intent to put them all in.
HFN: Does the output have to be a technical report as such, or is it a working document that can just stay in place on the W3C web site.
DF: What did query do with their usage scenario?
PC: We extracted the from the Query requirements and published them as a separated WD as Query matured and the scenarios became answers as well as questions. Expect that as query approaches closure, expect to archive Requirements/Scenarios as a Note.
DF: General assent that we don't want to change the direction of the primer. The usage scenarios seem to be a large and important contribution that we advance the Usage scenarios toward being a W3C Note.
DF: Proposes to advance Usage Scenatio on a W3C Note track.
No dissent recorded. Boston, Renes, Zakim...
12:40 Abstract Model
SKW: AM essentially unchanged since initial publication. Material is perhaps being reflected in the work of the TBTF. There are some outstanding editorial issues to be work, but the AM subgroup concluded around the publication of the WD pending further request from the WG.
DF: Proposal that we postpone further discussion of AM until TBTF and part 1/2 are a little further along.
No dissent recorded.
12:50: Requirements Documents
Jeff?: Question of requirements from other W3C WGs.
DF: P3P, XForms and RDF requirements all have the same sort of flavor... association of P3P profile with XMLP message... arbitrary bindary content and inclusion of RDF model in a message. We will have to show that we meet these.
DF: With RDF we are addressing this through use cases.
DF: Perhaps we can invite P3P and XForms to do likewise.
PC: Suggest that we can send a message to the XForm and P3P WGs stating that we believe these things can be done and put the onus that these WGs indicate why they think that it might not be possible to meet their requirements.
DF: Need to action somebody to contact P3P and XForms WGs... volunteers
ACTION: Chris Ferris to liase with P3P and XForm WGs.
DF: Maybe we need to add a couple of bullets to section 5 covering RDF and UML/MOF.
PaulD: Whatever happened to XML Ecryption liason.
DF: David Orchard took responsibility for this... don't know the current status.
ACTION: Paul Denning to ping David Orchard on status of XML Encryption liason.
DF: Should update requirements document: 309 change and update requirements from other W3C groups(RDF, UML/MOF (?), XML Encryption? P3P, XForms...).
ACTION: Editors to update requirements document re 309 and other W3C WGs (other bodies).
PC: The set of WGs that we've just listed need to be explicitly requested for comment as we go to last call. We should telegraph our intentions to the chairs of those WGs to ensure that they can provide a timely response.
DF: Proposal that we republish the requirements document when we have made all the changes just actioned.
No Dissent: Boston, Rennes, Zakim...
13:05 Lunch
14:00 TBTF Introduction Text (Glen's presentation ppt format, slide1, slide2)
GD: Audience for Framework is folks that are writing binding specifications. Like to create a framework that allows the creators of binding specification to expose the functionality/features of the underlying protocol.
- Intro's features.
- Feature Example
PC: Question... so you are not suggesting that the software is going to send a different SOAP message to different bindings.
GD: ...Maybe. You can imagine a number of way
HFN: A slightly different response is that it is up to the communicating parties to decide...
NM: Paul's question goes directly to an issue that we have in an ed-note where there may be differences between the views of TBTF members. The only disagreement within TBTF is about the claim that a given binding supports a given feature when it's carried as SOAP blocks inside a SOAP envelope.
GD: Does that answer your question Paul...
PC: Well yes... but you are waving your hands very nicely... I think that this may work of some of the features you run up against, but I don't think that there are going to be that many features that reach that far down into a binding.
GD: The binding framework is representing the system as a distributed state-machine.
Dug: When you come up with text... features can be represented as SOAP blocks... this is just one choice.. right?
GD: yes...
HFN: ...
NM: We can point to the text on this... there are some paragraphs (Noah quotes from Intro text).
PaulD: Trying to picture intermediaries... how do these factor into this...
Discusssion of End-2-End v hop-by-hop features... centred around authentication example.
HFN: We have been discsussing this for a huge amount of time with a lot of 'blood, sweat and tears' on this. I think it is telling that with respect to the questions that have come up... we have been able to point at text.
PaulD: Module... I don't see the term module in the text...
.... (difficult to capture the question... and response).
GD: Yes we have this model around exchange of named properties etc. For some folks specifying this this way was going too far. We are choosing to present our bindings that way, but we are not mandating that
Marwan: Question: what happened to message exhange patterns.
GD: We are treating message exchange patterns as features...
Marwan: So do you have some common properties features etc. what this needs is an example of a binding that shows how to form a SOAP POST message.
NM: Relating to some of the questions that have been asked. For a while we were carrying around a property based framework that named and typed properties etc. In the adjuct part of the spec is to provide an HTTP binding described using a property based convention. We are going to use this property based approach to spec.ing the HTTP binding. The use of the convention is none normative.
Marwan: So I agree that this a good idea that this is not in the core.
Marwan: If someone wants to create an HTTP binding that want's to use GET... does the framework allow such a binding to be created?
GD/NM/CF: Yes...
Discussion of bindings supporting different sets of features...
PaulD: Will there be words in the transport binding framework about the reuse of the various features...
More discussion....
PaulD: Also wondering what goes in the primer about bindings.
HFN: Just a comment on where SwA comes in. SwA was written after SOAP and is an orthogonal sort of a thing. But there are certainly ways
HFN: There are a variety of way to do this
CF: There are certainly ways to augment the binding. If you look at the HTTP binding... the door is open to doing SOAP with attachments.
GD: Just to quickly broach the primer question... I'd like to see some examples that illustrate how software can make use of this and specifically how the HTTP binding works.
Marwan: Question about modules...
GD: Refers to earlier work on module/binding templates.
Marwan: Writing a SOAP service, is it easy to write interface descriptions that says what binding is being used.
GD et. al: Yes...
Marwan: Who writes a binding....
Discussion
NM: Are you asking about bindings or binding specifications.
PaulD: Message exchange patterns... does the RPC spec have to refer to these features...
GD/NM:... well yes... that would be good.
DF: The questions that you are asking suggest a degree of understanding with some depth... the question that I am circling toward is "Is this the text that we'd like to see headed into Section 5".
PaulC: So where in this document are there going to be statements about testable assertions. We may be serving ourselves here or are we serving our public.
NM: My view would be absolutely normative... not every W3C spec needs to have a set of testable assertions....
PaulC: So this is an infoset like thing... so to get out of CR you are going to need to show it's use in creation of binding specifications.
NM: Yes... and we're going write and HTTP binding and maybe another.
PC: ....Noah... you've answered my question.
Some discussion of the other pieces, the concrete binding and feature pieces for the adjuncts pieces.
Dug: Suggest drop using the word introduction.
Agreed...
PaulD: Message exchange pattern, is that going to be spec'd in part 2?
GD: The currently drafted HTTP binding spec is written with a supporting description of a message exchange pattern - which is a great example of a feature.
Dug: There are some features that may be outside the scope of a binding - correlation ID...
GD: Feature set we have has a simple concept of request response. We don't say how that is transmitted. We can envisage a SOAP module that provides the functionality of a feature.
Discussion of features centred around message correlation.
Marwan: We see the word feature being used for both binding things and for module like things. I would prefer to see different words being used.
HFN: I disagree...
Discussion of the partitioning of functionality/features between binding and SOAP envelope/module.
PaulD: Is this more of a SOAP Extensibility Framework.
GD: ....
PaulD: Features seems like a pretty important thing here.
HFN: Yes... I think a key thing of SOAP is extensibility. So yes this is in part elaborating on an Extensibility Framework.
DF: We have already committed to entire read throughs....
NM: I see this as related to the ednote that we have in place. I would prefer to use the word 'feature' in a broader sense and that has to be introduced more broadly outside of chapter 5. eg. reliable delivery is a feature regardless of how it is provided.
HFN: Maybe we should take this offline. TBTF 5pm....
DF: Straw poll. General agreement to the Transport Binding Framework text, modulo standing ednote? If we give the group the thumbs up... generally then they can go away and work on resolving the ednote question:
General assent... some questions:
Anoush: If the intent of the framework to provide help to someone that is designing bindings to a particular protocol. What is more helpful is to look at the HTTP protocol binding example. However, this document is so abstract... it doesn't really help me address the goal of creating a binding.
HFN: The SOAP Processing Model in section 2 is similarly abstract... it doesn't specifically address how to create a particular module.
GD: That secondary section that describes a feature and then the HTTP binding gets you much closer to a concrete binding.
John I: Want to clarify: Folks constantly appeal for an example of how to do it in HTTP. However, there's a bunch of inbuilt knowledge about HTTP.... This is a framework aimed at being more explicit about the things that are perhaps more implicitly understood.
GD:
NM: That's kind of what we're doing. The framework answers all sorts of interesting questions: relationship of the binding to the SOAP processing model; infosets and serialisation;... the framework is not a cookbook... and yes we may need some transport binding spec. writers primer.
DF: Anoush does that answer your question...
Dug: I don't think that this stuff is as useful as folks seem to think it is but I'm not going to vote against this.
DF: We're doing a rather narrow thing here... we are focussing on the piece for part 1, we do have some of the other concrete stuff, but we're not focussing on that right now.
MH: This bears on the issue I raised earlier that this shouldn't go into a published WD without the other adjunct pieces.
PaulC: Concur.
DF: Turning this into a proposal: That we accept this as the basis for part 1 section 5, but don't ship it in a WD until we have the other adjunct pieces near ready to go, and that the TBTF prepare a plan and time-line for getting adjunct pieces into shape.
NM: I'd like to explore the with the TBTF what we could achieve in the very near future.
DF: The TBTF seem to h#}ave picked up a to-do... to prepare a plan...
General assent... on TBTF proposal.
15:30 Break
16:00 Issues
Issue 101.
DF: Recap where we had got to on the call. Asymmetric nature of header/body. JJM had a concern about whether we would allow more than one body block.
Dug: I don't think there is anything in Noah's proposal that precludes more than one immediate child of the body container. That should address your concern.
JJM: Yes... but there is also another proposal to allow only one body block
DF: To be clear... there is only one body element, but there can be multiple immediate children of the body element. So does the ability to have more than one body block meet your needs.
JJM: Yes and I can live with the proposal.
SKW:
HFN: Suggest we don't talks about body blocks, we don't speak about body blocks.
NM: We used to have text that stated that the body is just a header. Required recognition of QNAME and had implied mustunderstand.
HFN: I think we're giving some guidance on how to use the body. It's pointed out that it's not to be used for boxcarring in several places.
NM: So take a simple body with one body block... do we say anything about it?
HFN: Well we say that the ultimate recipient must process it, but we don't say that how you recognise that you understand it, only that you do... you don't have to make that choice through the qname of the immediate body child.
GD: ....
JK: Agree with Glen that the dispatch for body has already happened at the transport level. The body is just data.... agree with Glen and he said it better.
NM: The RPC chapter makes it clear that the body is not just data... gives example. I'm suggesting that we agree that lack of understanding does not generate an mU fault. But... to process the body we have to understand the body. At present we are not saying how to behave if we don't understand it.
HFN: We have to have a uniform way of saying that the whole message succeeded or failed. I also agree that we have to have a way for a recipient that signal that it got something it didn't understand.
NM: So... the recipient must have rules for processing a body and if that body block is received in combination with other body blocks then I have to have rules about how to process those blocks in combinations...
GD: So I've got an XSLT transform service, I just run the block through the transform and return the result. I don't have to understand the body to do that.
NM: So I think that's consistent.
JK: For headers the qname of the header block selects the code to process to header.... For the body, the application has know how to handle it. Treat the body as a well-known block...
DF: So where do we stand with respect to the current proposal.
HFN: I think the proposal is in the right direction.... we might want to decide whether we want to keep the term body block.
HFN: The short version is it's sort of ok.
GD: It needs a little tightening and there is a suggestion that we get rid of the term body block.
DF: I want to have an AI about how to move this issue along.
HFN:...
NM: We need to have something that's crisp enough to describe what you do in processing body blocks.
ACTION: Noah to clean up 101 proposal text incorporating discussion between Noah, Henrik and Jacek.
GD: Related point... processing order. Can a header be processed after a body? eg. checksum.
JK: Also are body blocks processed atomically...
NM: Can header/body processing in some sense be interleaved etc. eg transactioning.
NM: The proposal I would make is that all the header mU checking must occur first, but the processing of the blocks may be interleaved and the processing of headers may be interleaved with body processing.
Dicussion....
NM:
Dug: So after mU checking things are pretty much a free-for-all.
JK: Atomicity of the processing of blocks.... (fast paced dicussion...)... Jacek concurs with Noah... non issue.
Recap:
All header mU checking must be done 1st and atomically.
Understanding of the body which may have multiple parts is at discretion of Node. Problems result in application specific client faults.
Body and header processing may be freely interleaved.
MH: Seems to me that we're going backward. With headers we have a fine grain mechanism for reporting header faults. For the body we seem to be being less specific.
CF: No...
MH: I'm think of a SOAP node that understands
NM: If we're restrict the body to a single body block then we can be as specific as we are with headers. If we have multiple body blocks the reduced specificity may be the price we have to pay for the flexibility.
JK:...
MH: ...I don't support weather reports and I don't understand weather reports for Boston. Fine grain/coarse grain.
JK:...
HFN: If you don't understand things in the body could define a specific fault.
CF: It has been my feeling that header and body should be symmetric and there should just be blocks. If we're dispatching on body... but what are we dispatching to... my point is... we have a well defined mechnaism for headers, but we have no mechanism for doing this in the main body of the message. If we had we could just blocks we could have an attribute to mark out just one block as being the main purpose of the message.
GD: So... could drop header container, just have blocks and then body which is the main purpose carried in the content of the body element.
CF: I'm suggesting that we have blocks and a distinguishing attribute.
CF: The way a lot of ways in which folks are using SOAP is to dispatch on qname of the first body child.
GD: When you get to the end of your processing chain, you have to have worked out where you are going to dispatch the message to.
JK: Glen just said it... you mentioned it with TCP/IP appplications can't all have IP addresses and port numbers. We're in the Web world and we use URI's to identify things like where to dispatch.
HFN: This dicussion is probably a good thing... we have a pretty flexible framework, you can do a lot of things. Also, we have header and body... what does it mean to have to understand 5 things. It might be easier to achieve interop... we have this shopping basket that we can put things into. I think that this separation (?) gives us more interop.
Dug: I'd be very open to making them all just blocks, *if* you can identify the point up to which I do streaming processing...
NM: A few things have piled up... I think we have agreed to stick a SOAP like architecture. I think that if we open this up it will cost us a bunch of time.
There are at least some circumstances when you want to dispatch on QNAME. You may know to dispatch in QNAME due to request URI...
Re what Henrik called Dug's hack of treating the body element as a block... we could go there but the group needs to give me direction.
Dug: I think I'd leave it alone... not do the hack... I could go either way.
DF: So we should wrap this up... Noah to go away and write this up. By when...
NM: Fighting chance during F2F... when is drop dead.
DF: Noon Monday 3rd Dec Eastern ahead of telcon.
16:50
Issue 18:
JK: Outine issue 18: Three new emails explaining what "top level" really meant... The issue is about clarifying top-level. We have two proposals. 1) clarifying top-level or 2) allowing multirefs and removing all references to top-level.
HFN: By inlining do you mean the same thing that you can do for strings and byte arrays?
JK: Yes... implementations have to be able to do this...
DF: refers back to ETF minutes and ETF agreement to inlined multirefs and discussion of number of passes on serialising and deserialising.
CF: The other aspect of this is that you can do this either way. Says that you can do in-line multirefs, but doesn't say that you have to do it.
HFN: So a receiver has to be able to received both in-lined and out-of-line multirefs.
JK: The receiver will not be affected.
MH: Some receivers might not support both.
HFN: Rather than in-line the fix is that we allow both.
CF: So we can resolve reference by id, a uniform mechanism.
HFN: Given that id's can be anywhere we can serialise these things anywhere.
JK: Proposal is to remove a restriction.
DF: The proposal we were putting forward to was to in-line multirefs.
MH: We're not explaining that you can put these elements outside of the path of the main inline serialisation root. Concern that folks will not pick up that references by id may point outside of the in-line serialisation.
CF: I think it's ok.
HFN: So the change is that a multiref identified by an unqualified local id attribute and that we remove the top-level constraint.
JK: Current spec restricts target of multiref to being a top-level in the serialisation. The proposal is to remove that constraint...
DF: Are we ready to decide on this proposal?
HFN: Clarification? Thread on SOAP builders was fairly small... is thing something that we should call out specifically. What was the feed back from SOAP builders. Responses were generally this is a good idea AND... the ANDs yielding three new issues.
DF: Any objection to closing Issue 18 with the proposal as recorded in email.
No dissent.
ACTION: Jacek to generate resolution text to xmlp-comments and originator of the issue.
DF: Editors note... more change coming down the pike...
17:08 Session Adjourns...
Chris explains dinner plans and new location logistics.
David presents TBTF schedule / master plan for integrating the framework into the Working Draft for December. The basic idea is based on sending a WD to the W3C on December 14th. To make the framework useful, as discussed yesterday, we need four pieces in the WD:
1) The framework text itself (sec 1)
2) The property/type conventions (sec 2) - description of the mechanism (infoset-style properties with qualified names and schema types) we use in the latter two pieces
3) MEP spec(s) (sec 2) - description of request/response MEP
4) HTTP binding (sec 2) - utilizes the MEP description
All these pieces basically exist already, and need to be edited/cleaned up a bit.
The necessary schedule for this to work is as follows :
Review period needs to start today to reasonably acheive the goal. Email goes to dist app today which asks for people to begin to review the already-published MEP spec / HTTP binding / framework text, noting that if there are problems/issues, they need to be addressed ASAP. By next Tuesday (12/4), TBTF will publish revised/cleaned up pieces to dist-app. The WG telcon on 12/5 will have agenda space for discussing any issues/comments about the pieces. These pieces will then be linked into the editor's copy of the working draft (via hyperlinks) by EOB 12/5. Review period 12/5 - 12/7. Final text should be ready EOB 12/10 (Monday) - fully merged into the specs. Telcon on Wed 12/12 will contain the go/no-go decision about publication of this stuff. Need to publish the WD on this schedule to avoid a) holiday schedule problems, and b) the W3C's publication ban at the end of December.
Paul : what about the rest of the changes (XMLbase, encoding, etc)
David : this is TBTF-specific schedule, the rest will happen in parallel. Even if no other changes are actually made, though, the WG is prepared to publish a WD.
Paul : does this assume the TBTF stuff is more important than the rest of the already-approved changes?
Henrik : We're going to try to get as much in as possible by the 10th. We'll parallelize as much as possible
Marc : The TBTF stuff won't be ready for a little while, so we'll work on other stuff up until that point.
Paul : Given this, can the editors meet this schedule, considering the changes we've already approved (getting everything in)
David : This is really the first part of the schedule - the "merged version" depends on the editors
John : Will the WD which is published be the "complete set" which we talked about doing a full readthrough of yesterday?
Marc & David : Yes, that seems right.
David : let's move on to issues?
Stuart : what if the WG rejects this contribution?
David : business as usual - we resolve whatever issues are raised, and continue on.
Issues, continued
David : Marwan isn't here this AM, so let's postpone 40. Next issue is 169.
Jacek explains the issue.
Paul : FYI, the dissenter (Asir) is not here, we don't know how serious the objection is
Paul : The technical problem, according to my developers, isn't serious (various others) : We've implemented it too, seems to work.
David : proposal is to close issue 169 with the ETF recommendation (keep forward-references, no change)
[NO DISSENT]
David : 169 is closed
-----
Jacek explains 170.
Choices : a) be careful, no mandate.
b) disallow refs between "serialization trees" (header blocks + bodies)
c) data which might disappear MUST be serialized as separate Header blocks, targeted at "../none"
ETF chose (b).
Henrik : forward refs are nice so Header can point to Body. This disallows that use-case. The web fundamentally has one-way links, and they might break. That's life. Saying "you can use another encoding style" is a hack...
Noah : agree with Henrik, driving ourselves crazy over dangling links seems fragile. There are deeper questions - why are we going to lengths to allow these refs across trees anyway? We can't preclude app-level stuff, but when we encourage it in our spec.... Basic question seems to be is it a good idea to have a single data graph which spans headers which are targeted at different places?
Jacek : "serialization tree" is a graph of data which has been serialized, so how can it point to something else without increasing the scope of the graph?
Doug : dangling refs can happen for an unlimited number of reasons. Option (a) is better.
Chris : weird to say "you can't do that" in one part, then "you can do whatever you want" in another. (a) is better.
Mark B : agree with Henrik. Restricting the ability of one header to refer to another severely restricts the extensibility model.
Noah : will a header ever use sec-5?
Jacek : headers will use data, but not nec. sec-5
Glen : seems silly to restrict sec-5 when we allow arbitrary stuff in other encodings
Oisin : (a) is viable solution, but the real question is how do we fail in a predictable way when a ref is broken?
Marc : we're off the point slightly. Real question is should you allow multirefs to be in different blocks? Seems bizzarre to allow that.
Doug : do we want to disallow HREF -> attachments?
Noah : We're overloading HREF attribute. Chapter 5 "hijacked" the interpretation of HREF - it's a graph edge. Makes me nervous we're using the same attribute - now we can use the same attribute within a graph to point to something that's outside the graph.... maybe there should be a different way to express this. "in-graph" links, and "general" links.
Jacek : In soap encoding, referenced objects have xsi:type (explicit or implied). What's a web-reference (or MIME reference)'s type? It's totally different. If we go with (b), SOAP + Attachments will have to come up with another way to reference attachments.
Henrik : slippery slope to define different link categories - we end up with lots of different types...
Noah : at the web architecture level, yes, links are the same. As a practical matter, as a programmer it gets very complex when using this stuff for encoding RPC data graphs. The value of SOAP encoding is that helps people who want to send a certain kind of data (mapping well to programming languages). It's not every variation of link, but a clean subset.
David : there seem to be two sides here. One says links are links, the other says we're delivering an ecoding scheme, and linking can be subsetted within that scheme. We can argue this forever. We need to agree where to draw the line, and get this resolved.
Henrik : PROPOSAL - a general encoding where we don't say anything about links. Then in RPC convention, we say that you restrict links to the message. I.e. apply a convention to the encoding for RPC.
David : is that another encoding?
Henrik : maybe
Marc : That's good, but we do need another encoding style.
Noah : Don't need to tie this so tightly to RPC. There are two encoding styles, and RPC simply refers to the second one (more simple to deserialize, etc)
Chris : we seem to be overloading HREF. PROPOSAL - let's make serialization stuff an IDREF, and HREFs are separate. Off-the-shelf XML parsers could consistency check IDREFs....
Stuart : do we have a means to carry around a link as a data value?
xsi:type=ANYURI
Jacek : we can use a special xsi:type for referenced things?
PROPOSAL : take HREF out of the data model, replace it with another attribute
("GREF" for Graph REF?)
Henrik : this goes the wrong way, as it restricts things. We wouldn't be able to serialize RDF, because it has resources as links....
Two RDF scenarios...
Mark B : What about (d) rely on header designers to say what happens with broken ref?
Various : that seems close to (a)
Glen : what about the use-case for automatically deserializing an attachment? xsi:type + href seems to do this, but I'm not sure these proposals allow it...
Noah : henrik's proposal seems to - there are two encoding styles, one of which is more restrictive, but they both have the same data model. (i.e. you can still do it with the general one, but the "RPC-graph-limited" one disallows it - you can use either)
Paul : We need to fill in the blank "Data model" section.
Noah + Marc : there's a proposal out on dist-app for that already
Marc : if you can do either style, that doesn't make it any simpler?
Noah : point wasn't to make it simpler, was to make the fast case fast. This helps you optimize, and perhaps we don't even mandate support for both
Jacek : will most implementations implement both encodings?
Noah : PROPOSAL - one encoding, but clarify that implementations are required to resolve links within the envelope, but may (but need not) resolve links outside. (note : this is when using the encoding)
Glen : seems like we're moving toward (a) - in other words, we recognize the importance of linking to data which might not be there (either because it's missing from the envelope), so let's move on with it
Henrik : PROPOSAL - let's vote, and assign AI to write clarifying text.
Noah : does the proposal include defining the data model?
PROPOSAL : Accept (a) (don't change anything) and someone writes text which clarifies:
- You MUST resolve local refs
- You MAY resolve other refs
- Description of faults which references entail for consistency
[NO DISSENT]
ACTION ITEM : Jacek will write clarifying text for issue 170 resolution by EOB Monday.
------
Continuing on with ETF issues: 171
P1 : Proposal is to ignore other attributes on references aside from href, enc:position, and xml:base.
P2 : Behavior should be mandated by XML schema, noting that xsi:type handling is particularly tricky
Glen : what about typing attachments?
Jacek : there's a separate issue for this...
Henrik : how can they be separated?
Doug : What if you ignore the type on the referent element instead?
Stuart : why give a closed list of attributes which you should NOT ignore, instead of a closed list (i.e. xsi:type) which you SHOULD ignore?
Jacek : there may be a lot of attributes which can affect the value from an XML POV. We don't want to modify the list with every spec the W3C produces.... this list seems more closed than the other one.
Noah : this discussion leads to a slippery architectural slope... schema attributes like xsi:type are not under our control. "Of course, any namespace-qualified attribute which appears has the meaning of it's spec. Period, EODiscussion." Users should not use attributes which don't have the intended meaning. In particular xsi:type="int" can't have an href attribute.
Henrik : agree, too much risk that the spec owners might change/say something that disagrees with what we say.
Marc? : There could be another type "soap-enc:int" which does allow hrefs.
Same problem...
Stuart : Why can't we just disallow xsi:type on href elements entirely?
Richard : let's get back to the basics, too deep into technical stuff. I classify these as implementation issues - i.e. perhaps not our problem. We're writing a spec, not an implementation. May be SOAP applications which never use this stuff.
Glen : we're trying to write an interoperable spec which helps developers build things.
Richard : yes, to a point.
David : clearly there's a balance point between being helpful and trying to describe every legal XML usage... the trick is finding it.
Jacek : both proposals try to limit what can legally be done. #1 is more comprehensible to developers, #2 is more "abstractly correct".
David : #1 explicitly states an error. This error would also be invalid under #2, but that wouldn't be explictly specified. We could come up with hundreds of other cases of invalid schema stuff - should we specify all of them?
Jacek : #2 is more correct. #1 is simpler/more understandable. However, I do understand 2, and would go for it.
Chris : We could do this by defining our own type attribute "enc:type", which replaces "xsi:type", or our own types "enc:int", etc. Also, we should point to the child node ("#1/child::node()") - i.e. the value.
Noah : this is an XML serialization of something. It's more appropriate to refer to the entire element "a", including the xsi:type and any other attributes. The original #1 is a link to a node in a graph which has both a value and a type - this example ("child::node") points to the text string "3", not a value.
Anish : seems to me it should fault instead of ignoring the attribute in the original example
Paul : The original example was much simpler... maybe we should discuss that?
Noah : we have a graph model. Elements like a and b name edges. Both of which in the original point to a value "blah".
Doug : feels odd that we do one thing for headers (use attributes on the original element, even if it's an href) and another for values (use attributes on the referenced element, not the href)
Jacek : it's layered - the processing model says one thing, the encoding model says another. No conflict.
Jeff : Noah, can you draw the "blah" graph?
Jacek : I support P2 if it's phrased correctly, but I don't think I can write it myself.
straw poll for P2 - unanimous
ACTION ITEM : Murali will draft text for P2 by noon PST Monday.
P2' (Glen's proposal for another attribute to help type hrefs which refer to external entities (i.e. attachments)) will be another issue.
-----
159 + 166
Options:
P1: status quo, list, describe the explicit connection between listed styles better (all serializations in restricted style are valid in unrestricted style)
P2: restrict encodingStyle to a single value
Henrik : This morning we've discussed the idea of encodings like this (i.e."links
inside message" vs. "generic links allowed"), so there's
a use-case. Having a list enables avoiding tricky negotioation algorithms
for figuring it out.
Jacek : nobody uses this feature, and no one on soapbuilders indicated that they would be using it. Removing it makes the spec a little simpler as well.
Doug : Does a tighter scoped encodingstyle replace or extend the list?
group : replace
PROPOSAL : Change type of encodingStyle to anyURI (instead of list), change text to indicate a single URI.
[NO DISSENT : 166 is resolved]
PROPSAL : Change "CAN" to "MUST"
[NO DISSENT : 159 is resolved]
ACTION ITEM : Jacek will send mail to xmlp-comments about issue resolution.
-----
97
PROPOSAL : Use XML schema's base64 (plus errata) re: line length.
[NO DISSENT]
-----
David : the plan is to tackle these next two, then approach the 14 issues that we haven't really touched yet at all. Planning to spend a max of 15 minutes on each issue [scribe's note: I'm dubious]. At the end of 15 mins, we will assign an action item to someone to deal with whatever the next step is.
144 / 161
Jacek : 161 will be dealt with by one of the potential resolutions to 144 (text goes away)
Problem for 144 is that the app needs to parse the string (i.e. "xsd:int[2,3]") of the array attributes.
(review Jacek's proposal)
Stuart : looks like a huge thread on issue 144 - how did the proposal survive the discussion?
Jacek : No objections to the general direction. The issue is whether we take the whole proposal or just half of it (i.e. no sparse arrays).
P1 : Revamp attrs, clarify rules (as per archived proposal)
P2 : Omit sparse/partially-transmitted arrays (i.e. omit attrs)
Henrik brings up Q about nesting (array of arrays), we resolved that it's possible.
Noah : what do we do with schema derived array types? Can we deal with them?
Jacek : proposal deals with this. Arrays are typed soap:Array.
Glen notes that this is a point of breakage with respect to backwards compatibility.
STRAW POLL: P1? What say we?
Paul abstains becuase he wasn't here for the debate.
[NO DISSENT - P1 accepted]
STRAW POLL: P2? Given that we've accepted 1, do we disallow sparse arrays?
P3 - Leave it here (P1).............2
P2 - Remove sparseses...............7
P2' - Allow sparses, with marker....4
DF: We seem to be leaning towards P2.
Paul : now SOAP 1.1 is broken for real, since there's a semantic difference.
< lots of vigorous discussion, ending up with no clear decision >
Glen : PROPOSAL : let's ask soapbuilders/developmentor soap list/apache soap lists who's actually using this stuff, what the scenarios are, and how painful it would be if sparse/p.t. arrays go away. Then we go on from there
[NO DISSENT]
ACTION ITEM : Glen will send the mail and collect the results by Wednesday
(12/5).
-----
21
Issue seems to be "why use XML envelope instead of MIME?"
Chris: Now that we have infoset, does this help? Don't need angle-brackets necessarily....
David : Someone should go tackle the note and tell Joe about the infoset stuff.
ACTION ITEM: Chris will write up a response to Joe, in which he describes the wondrous infosetness of the new spec. By next Monday (12/10)
-----
102
Noah: Preferred resolution is to describe Fault handling as part of the MEP description as per the binding framework.
Glen: +1
John : We need to be careful about not popping "too high up the stack" - i.e.
TPAs, etc.
PROPOSAL : Change ownership of this issue to the TBTF.
Paul D: General features might have a use for determining what to do with faults, not just MEPs... for instance a feature might indicate send all faults to a third party?
-----
103
HFN Clarify what message path means.
NH Has funny properties, post facto only... Lets not spend time now, leave this until we clean up spec. MEPs will help clear this up for us.
HFN Not the MEPs we have.
Noah: this was very confusing a year ago, we're making great progress.
Henrik : It's more a distributed processing model than a message path model, although you can certainly build the latter.
Noah: a little nervous that "message path" heads towards precluding multicast...
Henrik : it's up to the application to do that stuff
David : we can say this is largely done now, but when we get closer to the end, we can check to make sure there are no loose ends WRT MEPs and this issue.
Defer to after TBTF?
[NO DISSENT]
ACTION ITEM : Issue list maintainer will defer 103 until post-TBTF.
-----
105
PROPOSAL : This will be closed with the description of MEPs.
-----
108
Henrik : Section 2.4 now states this explicitly.
PROPOSAL : Close this, noting that its done.
ACTION ITEM : Henrik to send mail to xmlp-comment, which is done. :)
[NO DISSENT]
-----
142
Henrik: there's another issue coming up about fault extensibility, etc. It might be better to wait until that one is here.
PROPOSAL : postpone this until the other issue comes out
ACTION ITEM: Update Henrik's action item to note that 142 is referenced from the new issue
ACTION ITEM: Assign this to WG
[NO DISSENT]
-----
155
Doug: want the optionality.
Noah: very nervous about that.
Henrik : We don't preclude anyone from taking on a role. SOAP prescribes one way for doing explicit targeting - there may be, due to out of band communication or other mechanisms, other ways for deciding who does what. It's not always that the sender knows the full set of combinations.
Noah : the anonymous actor is different. Since you must be consistent, if you do it for one thing, you have to do it for everything. If you do "soap processing" as the anonymous actor, you must process the body and the message must stop there. Any node can make decisions and do stuff as long as it's "outside the soap processing model". Intermediaries, for instance, can cache the whole message....
RESOLUTION: The optionality of "can" in the text is as to whether you can target, not as to whether you use actor as the targeting mechanism.
ACTION ITEM : Doug will write up the proposed resolution for issue 155 based on the consensus as if sec 4 was sticking around, and send it out by EOB Monday
-----
160
Noah : why not just delete this, since it's covered in sec 2? Define lexical structure in sec 4, with a reference to section 2 for a description.
PROPOSAL : Use section 4 to represent primarily the infoset description of the envelope. Where the interpretation of these things overlaps with chapter 2, put in a reference to chapter 2.
[NO DISSENT]
ACTION ITEM : Doug will send mail to xmlp-comment indicating the resolution by Friday.
-----
138
Paul : Has the group decided what to do?
Chris : We've decided on application/soap[?? +xml?]
Paul : How far down the + route do we go? +schema1 +schema2, etc. etc.?
Paul : Thought we'd agreed we shouldn't use application/xml, should use something else. Had not decided about + yet. We'd done the research, and decided not to use application/xml.
David : Hugo went to seek input from other WGs.
John : Didn't Mark N take an action to get a MIME content type? (application/soap+xml)
Henrik : AI was to ask xmime list what the status was.
David : Assign an action to pick up loose ends?
ACTION ITEM : Mark Baker will pick up loose ends re: content type with IANA and
XMIME feedback, W3C WG feedback, etc. by 12/10.
PROPOSAL : close 138, since we no longer use text/xml.
[NO DISSENT]
ACTION ITEM : Mark Baker will write up the resolution text, send to
xmlp-comments, and Murata-san by EOB Monday.
-----
Marc : Mark N was also looking into an HTTP status code (427) for SOAPAction-required.
ACTION ITEM : Raj will follow through on the ed note in section 6.1.1 of the adjuncts doc, inquiring with IANA to see about the status by EOB 12/10.
09:10 Schedule Review/Publication Decisions
DF: Presents Editors TODO list (major items)
101 Body/Header
130 Dot Notation for Fault Codes
134 XML Base
144 Array
146 Anoymous Actor
153 & 160 Section 2/4 duplication
-----
48 Optimal nature of encoding, data model....
Editor believe that the can address all above the broken line and TBTF materials next spec. WD publication.
MH: Explains why 48 is below the line... absense of Data Model text.
MRM: On 153 & 160 will be making some contribution to helping the editors as a consequence of working on 101
PC: Namespace... I assume that we'll be changing that. Are there any Schema changes?
...: No... but maybe we should ask Gudge.
MH: ArrayType may/will require schema changes.
PC: Assume that all below the line includes everything else that is outstanding....
MH: More examples from ETF, Usage scenarios, the encoding section mixes up encoding and schema to such an extent...
DF: That's assigned within the ETF, plus there are a bunch of things that the editors have spotted and will take ownership of.
DF: What number encoding examples? Answer 55.
PC: The timeline you have suggests not publishing again between this forthcoming publication and the end of Februrary.
DF: ...another thing implied by John Ibbotsons question is that this comming WD is the one that we will 'pound' on. That will obviously lead to further change.
DF: So this is the proposal from the TBTF and the editors... we need to decide if this is how we are going to proceed.
DF: Calls the question....
General Assent, no dissent (Boston, Zakim...)
09:20
DF:... Thank you... editors and TBTF are going to be busy...
HH: We have to talk about skiping CR and going straight to LC...
PC: I made this point on Tuesday and that it would be good to telegraph to the chairs of other WG.
HH: I think that we should signal our intentions to the public...
NM: Do we really want to provoke a process discussion... probably better to do with some well framed notes to the CG to consider...
DF: Hugo, could you look at the suitability of the status section indicating intentions to skip CR.
ACTION: Yves/Hugo to evaluate status section suitablity for CR skip notice.
09:25
Issues List
Issue 137: Intermediaries relaying SOAP Messages without modification
CF: Reads description of Issue 137 from Issues list.
NM: Quotes some material from Section 2.5
PC: Can we word this such that any nodes subsequent nodes process the same infoset?
NM: ...well not really.
NM: If we look at option 4 (in 137 issue text). We already state that processing order is at the discretion of the node, however, we do allow header blocks to have semantics that allow the imposition of different processing order constraints. Its possible to define a header to say 'begin end-2-end encryption'.
This would mean that th
HFN: Short version is roughly changing MUST to SHOULD... I think this a reasonable thing to do.
NM: These not quite the same thing to do...
GD: Comments
MRM: Difference is that my proposal requires the presense of a header before I do 'tricky' things.
HFN: Counters...
NM: So does that lead to interop... out of band agreements...
JK: Re: Noahs proposal. The default order is unspecified. In constrast in processing model we are quite strict. In think MUST to SHOULD is ok...
Dug: I think we should do MUST to SHOULD because it might not need to be triggered by an extension - eg encrypt every message.
NM: Counter example... based on some encryption of alternate headers... If I have a contract then I think I need to have a header to say I'm ok with that. Every time I hit a SOAP node I have a contract. I have a big problem if you allow nodes to change messages in arbitrary ways without a contract that I am party to.
CF: I like 2, persevation of the infoset?
NM: With encryption the infoset is not preserved along the path...
CF: I need to finish... the Infoset needs to be restorable.
NM: So where are the keys...
CF:
DF: Chair reminds on rules of engagement... time bounded
HFN: General model... intermediaries are 1st class object and you know that may be there...
NM: I disagree...
GD: We cannot prevent hidden proxy like things... we want to write a spec that makes these things a little out of spec.
NM:
Jeff: This preserve the infoset is kind of seductive, but is it testable... hard to enforce this...
Timeout.... heading for email...
DF: Would be useful to have an email to start a thread that presents both sides of this discussion.
MH: Just a quick thought... are we at the distinction between a SOAP intermediary and an Application Intermediary... ie.
NM: Among the reasons that we have all this actor, soap intermediary stuff is because we wanted to be able to do this at the SOAP level....
09:45
Issue 154: Role invariance during processing.
Dug: Original problem was the invariance role... I'm not so sure that I have a problem any more.
NM: Explains invariance... that all headers targeted at actor B get or none must be processed at a given node.
Discussion: Basically all headers targetted at a role must be processed at a node that assumes that role.
PC: can't we add a sentence....
Jeff: Question on interleaving roles... dureing processing.
NM: If a Node acts in role A it must consistently
CF: Suggest, "a role assumed must be invariant through the processing of the message".
NM: We have always tried to be declarative...
CF: You can change roles between messages... point having assumed a role you must process the message consistent with that role.
SKW: We're in danger of revisiting Issue 140 which addresses the determination of role by a SOAP node.
NM: Some reluctance to touch the text because it has been carefully crafted...
NM: Nodes are free to inspect any of all of the message
MH: Last para of Section 2.2...
NM: How dow we tie this together with the invariance piece.
NM: resumes: Nodes are free to inspect any of all of the message in order to determine the roles they play in processing a message.
NM: Requotes standing text....
NM: Issue hinges on the specific meaning of processing...
Dug: Invariance seems to suggest that I change what roles
NM: Quotes Section 2.5 (again)... including cavaets... I really don't want to mess with.
GD: Sounds fine to me...
Dug: I'm on the brink of saying drop this issue mark it closed.
DF: Propose primer text...
NM: Could add a sentence that says a node may inspect a message to determine role prior to processing..
ACTION: Dug... propose primer text addressing actor/determination/message processing by 7th Dec 2001.
10:05
Issue 41: No normative target URI.
NM: Does anyone understand to issue... tempted to suggest we have nailed it in the binding.
HFN: Could say that determining where to send a message is a feature....
GD: We where discussing what set of features is core... destination may be one of those things.
HFN: yes... but don't want to make a decision about that right now....
NM: Want some freedom to denote destinations later...
DF: Suggest that we go to email...
CF: I think I understand his point... the URI on a hop by hop basis will be evident somewhere, however the actual endpoint, the intended recipient is never denoted in any consistent fashion.
HFN: I think that calls out a decision that we have to make. We have 'gradually' been specify this over time in the TBTF...
GD: I agree with that and this may be another thing for the primer... examples etc.
DF: Clearly what Vidur is looking for is some standard/consistent way of denoting where to send a message.
HFN: I don't think he's calling for a standard way of saying where to send a message in the envelope. The decision I think/thought that we are making is that we can do this by using our extension mechanism.
CF: ...what I think Vidur is getting at is that while we can do this any number of ways, we need a consistent way of doing this. Addressing is kind of special...
Nilo: Section 5 part 2 it says that SOAP relies on the binding to provide a mechanism for carrying the URI...
SKW: Section 5, part is a little far in to be saying this.
CF: Its more than just for RPC.
CF: Didn't we talk about RPC being an MEP binding... in TBTF?
NM: RR yes, RPC no...
DF: The RPC task force quiessed an left a few issues still open...
NM: We need to make sure that the binding framework etc is finished that it needs to be self consistent about where messages go. Is there an RPC idiom that we want to call out? Doing RPC, you need to know what binding you're going out over. My recommendations are not to do anything magical in core SOAP that we lock out the options.
HFN; I think that we have a pretty robust answer. We know that there are may things that we can do in many different ways. We don't give you a postal service... we give you an envelope.
NM: ...I think we need to take some care as we close the binding material...
HFN: Proposal: Either revive the RPC TF or catch during read through...
JK: Have already said that RPC will refer to a request/response feature... close the issue.
NM: ...basically that RPC is layered on the RPC feature... and then clean up as dust settles.
GD: Want to note that *if* you had a slot to put the URI. There is nothing in the processing/extensibility model to ensure that its not ignored.
DF: Suggest that we postpone this to post TBTF/MEP...
No dissent (Boston, Renes, Zakim).
ACTION: Issue list editor i41 to reconstitued RPC TF.
10:30 Break
11:00 February F2F information.
Issue 98: Content based routing...
DF: This seems to be about routing on payload content and that without a normalised representation, routing may be problematic.
JI: I think that this is outside our scope. This an application issue.
DF: I think this is what we said to i18n... don't make us do this.
PC: Not sure I understand the context for this...
HFN: Have we had any response to our response on canonicalisation....
DF: May have suffered because David Clay who owned the action had to leave the group. Need someone to take an AI to track down the remanents of this thread. Suggest that there are folks that have yet to take an AI.
ACTION: Paul Denning to pick up this thread with i18n, uodate by 14th December.
11:10
Issue 59: Mandate a particular character encoding.
OH: Discussion from dawn of time on whether or not to mandate a particular character encoding for SOAP/XMLP. Some discussion with i18n, but not concencus developed and we've moved onto other things. No particular proposal than to maintain the status quo... ie. its XML.
NM: So where we speak of infosets, we're entirely neutral, however this really goes with the bindings.
CF: What we did in ebXML we called out what we expect is that you put the encoding in the XML decl... invites Iwasa to comment.
Iwassa: I think it helpful to define some encoding. No specific proposal to define a mandatory encoding.
CF: I thought that UTF-8 was not enough....
Iwasa: eg. some folks support UTF8 others UTF16, then we have
PC: So what does XML say?
NM: UTF8 and UTF16...
PC: So why do we have to say anything?
OH: Binding should have a default encoding and possibly some scope to support others.
NM: Nearly agree... there are all sorts of representations that I could do that are not based on character encodings, eg DOM implementation over RMI... that would move an infoset.
OH: On extensible bindings... is an an HTTP binding that specifies UTF8 the same binding as one that specs. UTF16.
NM: Suggest... all implementations must be capable of generating one and accepting both....
CF: UTF8 and UTF16 are not always UTF8/16... this is not enough. You have to say what dialect of UTFxx, you have to know what character-set is applied to the encoding.
NM: ...I thought that XML was intended to establish a level of interop...
DF: Could flesh out this emerging proposal and seek feedback from a wider community.
HH: Clarification of XML spec viz UTF8/16 encoding of UCS multi-octet character sets...
DF:
HFN: Push back on assumption that this is very much a binding issue. This binding is a hop-by-hop thing and I may not want to have to recode messages as they pass through an intermediary. There's a risk that we make bindings very specific to particular character sets...
NM: I think that you raise an important point. The infoset is serving the spec. well... I think that folks will develop suites of binding specs that are intended to work together (multi-hop). It might be that I am building doms and reserialisating. I think this is largely an implementation issue... if you want to manipulate the serialised form.
OH: Offers to take an AI to take propose resolution on email.
HFN: Friendly ammendment. AI already on notation area of spec regarding infoset descriptions...
DF: Suggest Oisin take a proposal to the list.
ACTION: Oisin to generate initial proposal for email discussion, by end-of-week.
11:30
Test-Cases
DF: Propose that HH and OH give status report on test cases... then break into groups, each assigned 1-2 sections of the spec. Look for testable assertions and then start generating tests...
HH: Presents Test case document.
Recap... on previous F2F.
Extract testable assertions
There was a draft... now in XML...
Updated with latest version of spec.
Structured into several parts...
Assertion template...
49 Assertions...
2 currently have tests...
8 others covered by SOAPBuilders tests.
Means for folks to contribute tests... but no test yet contributed that way.
PC: Lawyer joke...
HH: Questions...
DF: Assigns groups...
G1: Part 1, Section 2 and 3,
G2: Part 1, Section 4
G3: Part 2, Section 4
G4: Part 2, Section 5
CF: For HTTP binding perhaps we should use TBTF draft...?
GD: Yep... there is a possible problem using text that we're going to discard.
PC: Encourage the groups to do a thin, narrative pass, then go back and develop the detail. Come out of today at least with narrative test... then address in parallel.
HH: Just a note that the assertions as numbered appear in document order.
DF: Division by first letter of surname:
A-F G1
G-J G2
K-M G3
N-Z G4
12:00
DF: Run for 30mins, take an hour for lunch and then review whether this is going to work?
DF: Work through on flip charts and do one assertion per page.
12:30 Mini plenary Discussion
- More assertions that MUST and SHOULDs
- Need for test harnesses
- Vague assertions that are untestable.
- Spec. issues.
[maybe others that my memory has failed to retain]
ACTION: Spec editors to investigate how to tie spec and tests together. Liase with SVG...
14:50 Wrap-up
DF: Assuming that each group will summarise their various to xml-dist-app. Option to continue working... for a while if sufficent folks left...
JK: wrt to encodings, it's pretty hard to generate test cases. Since it's an adjunct we may end-up without test cases for encoding.
DF: ...Why's that?
JK: Dependancies on schema etc...
JI: I think some consideration of the test environment...
CF: We were running into assertions that were essentially non-testable... eg. properly namespace qualification of generated messages...
JK: Noah described how XML Schema describes conformance test for Schema processors (but not generators of Schema?).
DF: Will need to reconsider the test cases in the context of what goes into the test collections document.
15:00
Revisit Schedule:
DF: publication of the test schedule.
Jeff: Seems to be an implicit idea of a conformance statement. I think that we should have a much clearer idea of what sort of conformance statements we are trying to make.
HH: The QA activity suggested that we *not* publish as a WD. Could publish as a note...
HFN: One factor is that this draft is not the goal, but a means to ensure interoperability. Part of a means to get through last call. Ultimately, do we have some minimum number (2) of implementations that cover all parts of the spec. Also the current document does not describe a test harness.
GD: Well yes... but we're all making it (testing) happen...
GD: I think that we're looking for some combined work with SOAP builders to do this.
DF: To clarify... our creation of this document is intended as a tool to the community that the community can refer to and assert their utility in creating interoperable implementations.
JI: There will be folks that will claim conformance with the test collection...
GD: Are there W3 test suites in other areas?
Dug: If this is to serve the SOAP community we need to publish early and often.
DF: Hugo needs to go back to QA for clarification.
HFN: Let's not loose sight of the fact that the reference point is our spec.
Normative/non-normative nature of test collection gets discussed (GD/HFN).
HFN: There's a difference between a spec for a set of test services and what it is that SOAP is.
DF: Need some general clarification in our own minds on the purpose of this document. It's proving useful at the moment in reviewing and finding issues with the spec.
ACTION: Hugo to ping QA about the publication of the test collection as a WD.
15:10 Schedule:
DF: Scenario 2 is clearly more reasonable...
Possible F2F prior to PR (West coast?) need a volunteer for a venue. Need to fix a date and coordinate with other XML WG meetings.
WD Publication of Part 1, 2, Primer, Usage Scenarios...
15:20 Adjourn.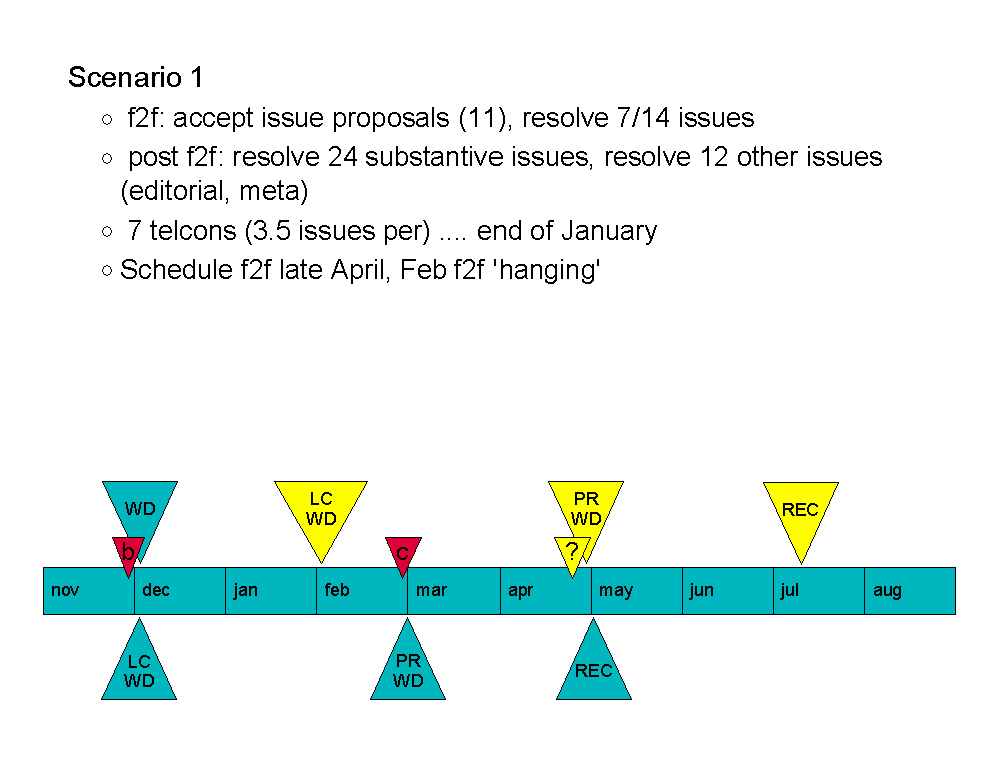{kind=link}
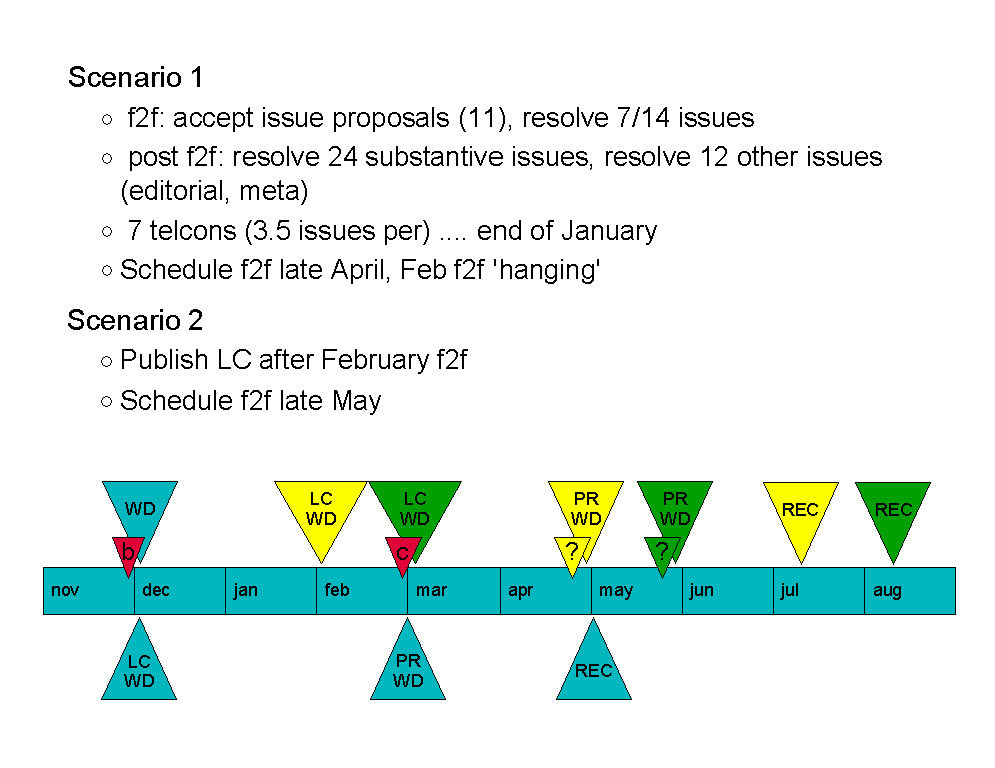{kind=link}
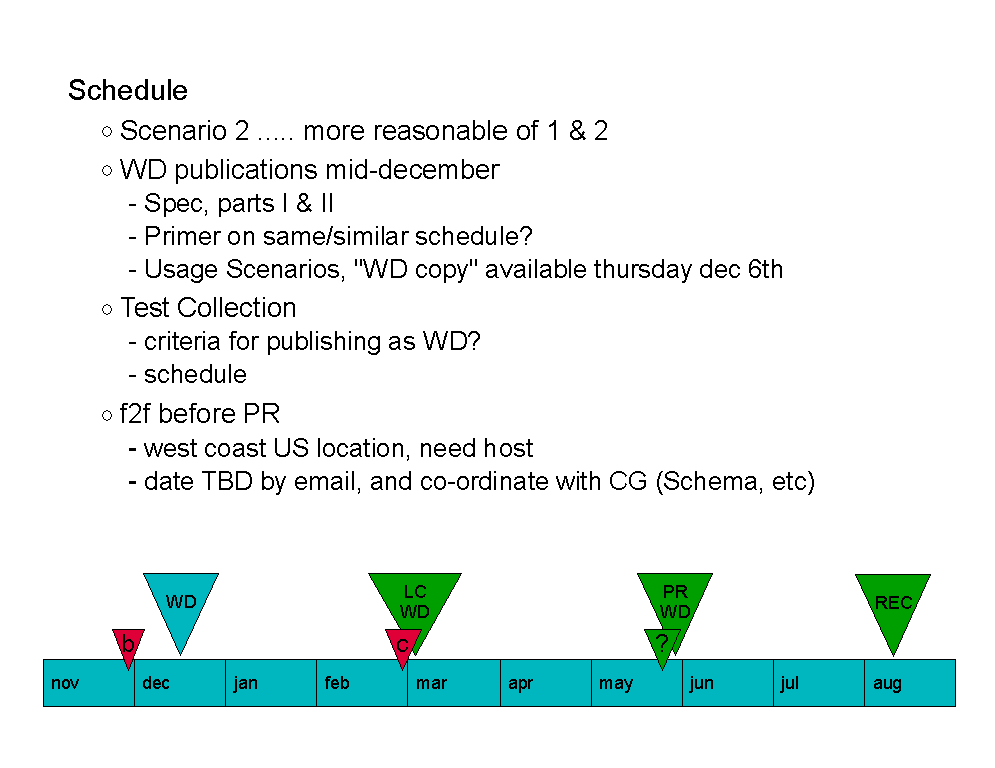{kind=link}
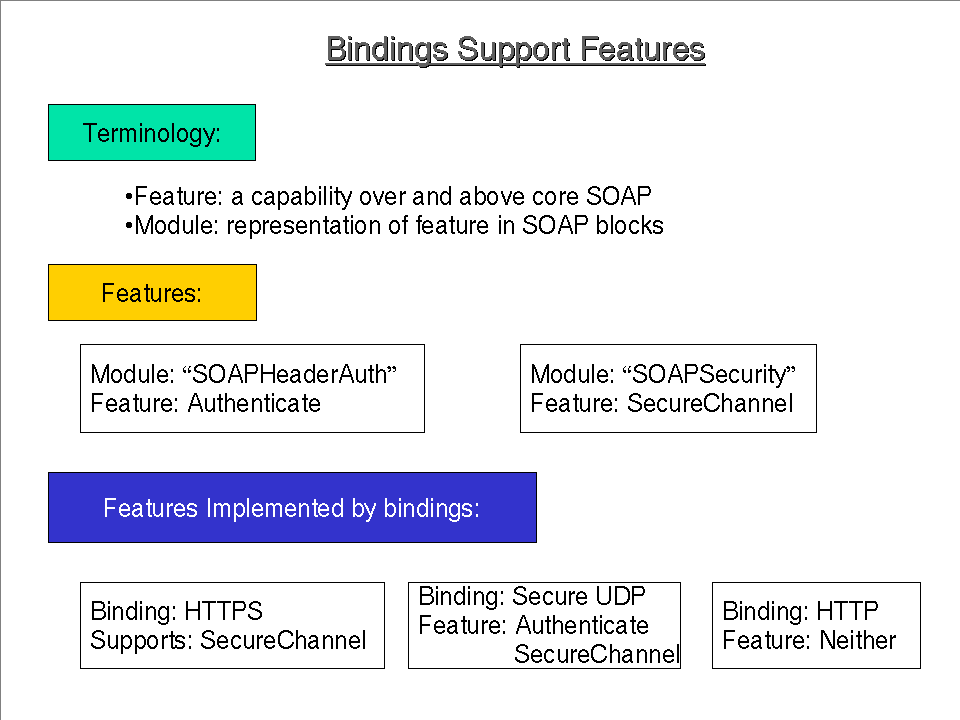{kind=link}
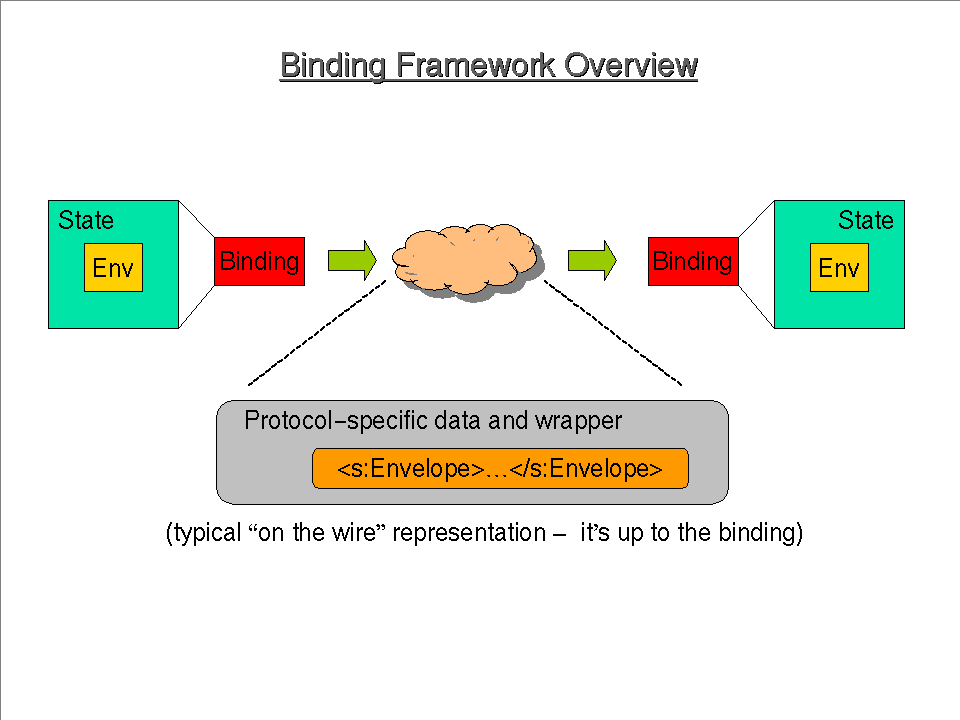{kind=link}