There are a many languages in use today for exchanging RDF-structured information. Here's a sample rendered in many different ways. Converters exist between some of these formats, but not others (yet).
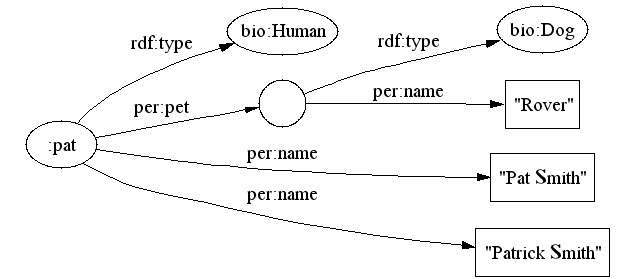
There is person, Pat, known as "Pat Smith" and "Patrick Smith". Pat has a pet dog named "Rover".
Here the ambiguity of terms is addressed by making the words be hypertext links. The links may or may not work, depending on the servers involved.
Pat is a human with the names "Pat Smith" and "Patrick Smith". Pat has a pet, a dog, with the name "Rover".
@prefix : <http://www.w3.org/2000/10/swap/test/demo1/about-pat#> .
@prefix bio: <http://www.w3.org/2000/10/swap/test/demo1/biology#> .
@prefix per: <http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#> .
:pat a bio:Human;
per:name "Pat Smith",
"Patrick Smith";
per:pet [
a bio:Dog;
per:name "Rover" ] .
<rdf:RDF xmlns="http://www.w3.org/2000/10/swap/test/demo1/about-pat#"
xmlns:bio="http://www.w3.org/2000/10/swap/test/demo1/biology#"
xmlns:per="http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<bio:Human rdf:about="#pat">
<per:name>Pat Smith</per:name>
<per:name>Patrick Smith</per:name>
<per:pet>
<bio:Dog>
<per:name>Rover</per:name>
</bio:Dog>
</per:pet>
</bio:Human>
</rdf:RDF>
With @prefix:
@prefix : <http://www.w3.org/2000/10/swap/test/demo1/about-pat#> . @prefix bio: <http://www.w3.org/2000/10/swap/test/demo1/biology#> . @prefix per: <http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>. :pat rdf:type bio:Human. :pat per:name "Pat Smith". :pat per:name "Patrick Smith". :pat per:pat _:genid1. _:genid1 rdf:type bio:Dog. _:genid1 per:name "Rover".
In standard form:
<http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2000/10/swap/test/demo1/biology#Human> . <http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat> <http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name> "Pat Smith" . <http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat> <http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name> "Patrick Smith" . <http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat> <http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet> _:genid1 . _:genid1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/2000/10/swap/test/demo1/biology#Dog> . _:genid1 <http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name> "Rover" .
Without namespaces, this is very terse:
human(pat). dog(rover). % we have to assign a name name(pat, "Pat Smith"). name(pat, "Patrick Smith"). name(rover, "Rover"). pet(pat, rover).
One approach to namespaces:
ns(ns1_, "http://www.w3.org/2000/10/swap/test/demo1/about-pat"). ns(bio_, "http://www.w3.org/2000/10/swap/test/demo1/biology#"). ns(per_, "http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#"). bio_Human(ns1_pat). bio_Dog(rover). # unprefix could be be NodeIDs... per_name(ns1_pat, "Pat Smith"). per_name(ns1_pat, "Patrick Smith"). per_name(rover, "Rover"). per_pet(ns1_pat, rover).
URIs are big, variable-length keys; it's much more efficient to translate them into an internal id. If the "uri" is NULL, this resource is anonymous (a bNode, like a NodeID in RDF/XML).
CREATE TABLE uri (
id INT AUTO_INCREMENT PRIMARY KEY, # PRIMARY = UNIQUE and NOT NULL
uri BLOB, # BLOB is also called LONGVARBINARY
UNIQUE KEY uri (uri(64)) # length is just a tuning knob
);
INSERT INTO uri (uri) VALUES ('http://www.w3.org/1999/02/22-rdf-syntax-ns#type');
INSERT INTO uri (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/biology#Human');
INSERT INTO uri (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/biology#Dog');
INSERT INTO uri (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name');
INSERT INTO uri (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet');
INSERT INTO uri (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat');
INSERT INTO uri (uri) VALUES (NULL); # this is rover, who has no URI
mysql> select * from uri;
+----+--------------------------------------------------------------+
| id | uri |
+----+--------------------------------------------------------------+
| 1 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type |
| 2 | http://www.w3.org/2000/10/swap/test/demo1/biology#Human |
| 3 | http://www.w3.org/2000/10/swap/test/demo1/biology#Dog |
| 4 | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name |
| 5 | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet |
| 6 | http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat |
| 7 | NULL |
+----+--------------------------------------------------------------+
This is a simple, intuitive approach, but...
CREATE TABLE resource ( id INT PRIMARY KEY, type INT, # http://www.w3.org/1999/02/22-rdf-syntax-ns#type name varchar(255), # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name pet INT # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet ); INSERT INTO resource (id, type, name, pet) VALUES (6, 2, 'Pat Smith', 7); INSERT INTO resource (id, type, name) VALUES (7, 3, 'Rover'); mysql> select * from resource; +----+------+-----------+------+ | id | type | name | pet | +----+------+-----------+------+ | 6 | 2 | Pat Smith | 7 | | 7 | 3 | Rover | NULL | +----+------+-----------+------+
Here we avoid having such wide tables, and our modeling better matches the normal database modeling. On the other hand, we have some conceptual redundancy between human.name and dog.name, because there is no support for inheritance.
CREATE TABLE human ( # http://www.w3.org/2000/10/swap/test/demo1/biology#Human id INT PRIMARY KEY, name varchar(255), # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name pet INT # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet ); CREATE TABLE dog ( # http://www.w3.org/2000/10/swap/test/demo1/biology#Dog id INT PRIMARY KEY, name varchar(255) # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name ); INSERT INTO human VALUES (6, 'Pat Smith', 7); INSERT INTO dog VALUES (7, 'Rover'); mysql> select * from human, dog where human.pet=dog.id; +----+-----------+------+----+-------+ | id | name | pet | id | name | +----+-----------+------+----+-------+ | 6 | Pat Smith | 7 | 7 | Rover | +----+-----------+------+----+-------+
Here we can support duplicate values.
CREATE TABLE name ( # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name subject INT NOT NULL, object varchar(255), INDEX(subject), UNIQUE INDEX(subject, object) ); CREATE TABLE pet ( # http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet subject INT NOT NULL, object INT, INDEX(subject), UNIQUE INDEX(subject, object) ); CREATE TABLE type ( # http://www.w3.org/1999/02/22-rdf-syntax-ns#type subject INT NOT NULL, object INT, INDEX(subject), UNIQUE INDEX(subject, object) ); INSERT INTO name VALUES (6, 'Pat Smith'); INSERT INTO name VALUES (6, 'Patrick Smith'); INSERT INTO name VALUES (7, 'Rover'); INSERT INTO pet VALUES (6, 7); INSERT INTO type VALUES (6, 2); INSERT INTO type VALUES (7, 3); mysql> select * from name; +---------+---------------+ | subject | object | +---------+---------------+ | 6 | Pat Smith | | 6 | Patrick Smith | | 7 | Rover | +---------+---------------+ mysql> select * from pet; +---------+--------+ | subject | object | +---------+--------+ | 6 | 7 | +---------+--------+ mysql> select * from type; +---------+--------+ | subject | object | +---------+--------+ | 6 | 2 | | 7 | 3 | +---------+--------+
If we redo our URIs table as a "resources" table, with literals as well as URIs, we have some more options.
CREATE TABLE resources (
id INT AUTO_INCREMENT PRIMARY KEY, # PRIMARY = UNIQUE and NOT NULL
# either provide a uri
uri BLOB,
# or a literal_value, which might have a datatype and language
literal_value BLOB,
datatype INT,
language VARCHAR(5),
UNIQUE KEY (uri(64)) # length is just a tuning knob
);
INSERT INTO resources (uri) VALUES ('http://www.w3.org/1999/02/22-rdf-syntax-ns#type');
INSERT INTO resources (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/biology#Human');
INSERT INTO resources (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/biology#Dog');
INSERT INTO resources (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name');
INSERT INTO resources (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet');
INSERT INTO resources (uri) VALUES ('http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat');
INSERT INTO resources (uri) VALUES (NULL); # this is rover, who has no URI
INSERT INTO resources (literal_value) VALUES ('Pat Smith');
INSERT INTO resources (literal_value) VALUES ('Patrick Smith');
INSERT INTO resources (literal_value) VALUES ('Rover');
mysql> select * from resources;
+----+--------------------------------------------------------------+---------------+----------+----------+
| id | uri | literal_value | datatype | language |
+----+--------------------------------------------------------------+---------------+----------+----------+
| 1 | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | NULL | NULL | NULL |
| 2 | http://www.w3.org/2000/10/swap/test/demo1/biology#Human | NULL | NULL | NULL |
| 3 | http://www.w3.org/2000/10/swap/test/demo1/biology#Dog | NULL | NULL | NULL |
| 4 | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name | NULL | NULL | NULL |
| 5 | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet | NULL | NULL | NULL |
| 6 | http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat | NULL | NULL | NULL |
| 7 | NULL | NULL | NULL | NULL |
| 8 | NULL | Pat Smith | NULL | NULL |
| 9 | NULL | Patrick Smith | NULL | NULL |
| 10 | NULL | Rover | NULL | NULL |
+----+--------------------------------------------------------------+---------------+----------+----------+
Then we can have a simple table of triples:
CREATE TABLE triples (
subject INT NOT NULL,
predicate INT NOT NULL,
object INT NOT NULL,
UNIQUE INDEX(subject, predicate, object),
INDEX(predicate, object),
INDEX(object, predicate)
);
INSERT INTO triples VALUES (6, 4, 8);
INSERT INTO triples VALUES (6, 4, 9);
INSERT INTO triples VALUES (7, 4, 10);
INSERT INTO triples VALUES (6, 1, 2);
INSERT INTO triples VALUES (7, 1, 3);
INSERT INTO triples VALUES (6, 5, 7);
mysql> select * from triples;
+---------+-----------+--------+
| subject | predicate | object |
+---------+-----------+--------+
| 6 | 1 | 2 |
| 6 | 4 | 8 |
| 6 | 4 | 9 |
| 6 | 5 | 7 |
| 7 | 1 | 3 |
| 7 | 4 | 10 |
+---------+-----------+--------+
mysql> select s.id, s.uri, p.uri as "predicate",
o.id, o.uri, o.literal_value as "lit"
from triples, resources as s, resources as p, resources as o
where s.id=triples.subject AND
p.id=triples.predicate AND
o.id=triples.object;
+----+---------------------------------------------------------+--------------------------------------------------------------+----+---------------------------------------------------------+---------------+
| id | uri | predicate | id | uri | lit |
+----+---------------------------------------------------------+--------------------------------------------------------------+----+---------------------------------------------------------+---------------+
| 6 | http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | 2 | http://www.w3.org/2000/10/swap/test/demo1/biology#Human | NULL |
| 6 | http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name | 8 | NULL | Pat Smith |
| 6 | http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name | 9 | NULL | Patrick Smith |
| 6 | http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#pet | 7 | NULL | NULL |
| 7 | NULL | http://www.w3.org/1999/02/22-rdf-syntax-ns#type | 3 | http://www.w3.org/2000/10/swap/test/demo1/biology#Dog | NULL |
| 7 | NULL | http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#name | 10 | NULL | Rover |
+----+---------------------------------------------------------+--------------------------------------------------------------+----+---------------------------------------------------------+---------------+
The striped or alternating-normal form approach uses a markup language designed for the application domain. Conversion to and from triples requires specialized software
<Human>
<uri>http://www.w3.org/2000/10/swap/test/demo1/about-pat#pat</uri>
<name>Pat Smith</name>
<pet>
<Dog>
<name>Rover</name>
</Dog>
</pet>
</Human>
An alternative is to use XML Triples. This does not involve domain-specific markup. Several candidate DTDs/Schemes have been proposed; this is just one strawman. For some applications, this kind of syntax may be easier than RDF/XML or a striped syntax.
<!DOCTYPE Graph [
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY bio "http://www.w3.org/2000/10/swap/test/demo1/biology#">
<!ENTITY ns1 "http://www.w3.org/2000/10/swap/test/demo1/about-pat#">
<!ENTITY per "http://www.w3.org/2000/10/swap/test/demo1/friends-vocab#">
]>
<Graph>
<Triple>
<subject><uri>&ns1;pat</uri></subject>
<predicate><uri>&rdf;type</uri></predicate>
<object><uri>&bio;Human</uri></object>
</Triple>
<Triple>
<subject><uri>&ns1;pat</uri></subject>
<predicate><uri>&per;name</uri></predicate>
<object><literal>Pat Smith</literal></object>
</Triple>
<Triple>
<subject><uri>&ns1;pat</uri></subject>
<predicate><uri>&per;pet</uri></predicate>
<object><nodeID>genid1</nodeID></object>
</Triple>
<Triple>
<subject><nodeID>genid1</nodeID></subject>
<predicate><uri>&rdf;type</uri></predicate>
<object><uri>&bio;Dog</uri></object>
</Triple>
<Triple>
<subject><nodeID>genid1</nodeID></subject>
<predicate><uri>&per;name</uri></predicate>
<object><literal>Rover</literal></object>
</Triple>
</Graph>
The RDF model maps fairly well to several common programming constructs, especially those found in interpreted object-oriented languages, like Javascript and Python. Still, this mapping is not perfect.
This simple approach ignores URI and cardinality issues; it only allows pat to have one name and one pet:
pat = Human() rover = Dog() pat.name = "Pat Smith" rover.name = "Rover" pat.pet = rover
We can begin to consider cardinality:
pat = Human()
rover = Dog()
pat.name.append("Pat Smith")
rover.name.append("Rover")
pat.pet.append(rover)
But to be more complete, we need something like this which loses the simplicity of the built-in model:
pat = Resource() rover = Resource() pat.addProperty( ns.rdf.type, ns.bio.Human) rover.addProperty(ns.rdf.type, ns.bio.Dog) pat.addProperty( ns.per.name, "Pat Smith") rover.addProperty(ns.per.name, "Rover") pat.addProperty( ns.perpet, rover)
Beware of thinking of RDF as a format for serailizing objects. The semantic web is different - it is weblike.
An object can be in many classes. When you create a semantic web document about something, others can deduce more things about it, in vocabularies you have never heard of.
Entity-Relationship and UML diagrams are useful for describing RDF -- so long as you remember the above.
One of the interesting challenges is how to blend languges such as n3 seamlessly into object-oriented procedural languages.