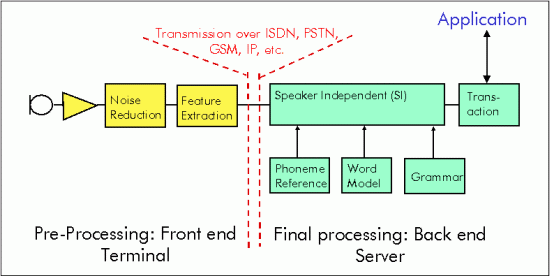
Fig. 1 Front - Back End split
ETSI STQ Aurora DSR Subgroup "DSR Applications & Protocols".
David Pearce
Chairman: ETSI STQ Aurora & Motorola
[bdp003@email.mot.com]
Dieter Kopp
Subgroup Chairman: Aurora DSR Applications & Protocols &
Alcatel
[dkopp@rcs.sel.de]
Wieslawa Wajda
Alcatel
[wwajda@rcs.sel.de]
ETSI STQ Aurora Working Group is a collaborative activity to establish global standards for Distributed Speech Recognition (DSR). The contributing companies consist of the major developers of mobile equipment.
The first DSR standard was published by ETSI in Feb 2000 and an advanced standard is now being developed. Reference 1 gives an overview of DSR and the work of Aurora.
A new sub-group called DSR Applications & protocols has been formed to address the issues of implementing complete end-to-end DSR services using these front-end standards. It is active in defining the necessary protocol elements, system architecture, API, etc. The approach being taken is to use existing or emerging protocols and standards whenever possible to enable speech interfaces to mobile applications using DSR.
DSR will have a significant impact in enabling speech interfaces to mobile terminals as it allows the computationally intensive recognition to be performed at a remote server with negligible loss in performance.
We would like to co-operate with W3C and WAP Forum for harmonising protocol elements and multimodal markup language for DSR applications.
A typical distributed speech recognition system consists of two functional parts: a Front-End (FE) and a Back End (BE) (see Fig. 1).
The Front-End transforms digitised speech into a stream of feature vectors. These vectors are then sent to the Back-End of a data transport which could be wireless or wireline. The recognition engine of the Back-End matches the sequence of input feature vectors with references and generates a recognition result.
While it is possible to imagine having a local speech recogniser on future mobile devices at present this would be a substantial additional cost due to processing power and memory restriction in current mobile devices. This can be overcome by placing the computational and memory intensive parts at a remote server. DSR both reduces the bandwidth requires and overcomes the distortion coming from the transmission errors over the cellular network.
The advantage of DSR against voice coding is shown in simulation of Voice Recognition over IP using a random error pattern and an error concealment strategy based on polynomial interpolation.
The investigation results is, that the voice recognition over IP using the DSR track 1 (8 kHz implementation on PC) feature extraction has a significant improvement compared to recognition behind a voice coding. At 50% packet lost only 3% recognition reduction was observed using DSR compared to 63% recognition reduction for using a G723.1 codec.
Fig. 1 Front - Back End split
To reach this aim we will develop user scenarios for, from our point of view, the most important mono-modal and multi-modal applications. They are:
These applications will enable the identification of requirements for DSR services and the protocols to support them.
For defining a protocol suite for DSR we have to select or enhance existing protocols to support the following:
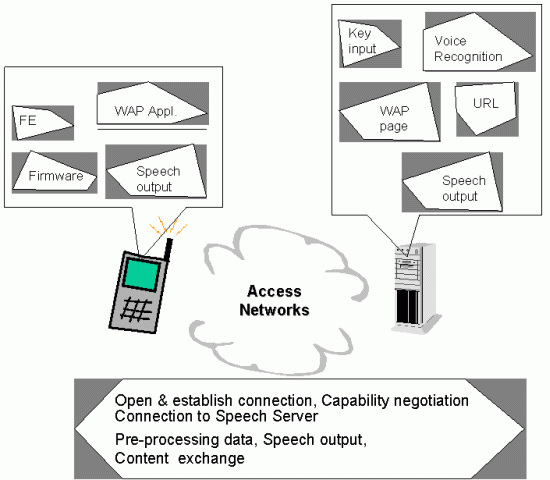
Fig. 2 Information exchange between client and server
Multimodal services using DSR will require a software component which enables and controls the communication between terminal and server and synchronises the speech input/output with the other modalities.
This software component can be described as a Speech Agent defining standardised Application Programming Interface (API) . The task of Speech Agent on the terminal is for example:
The API and the architecture of Speech Agent must be flexible enough to cover multi-modal architectures.
We propose to place the Speech Agent in the WAP protocol architecture as shown in Fig. 3. The Speech Agent lies on the Speech Abstraction Layer which is responsible for hardware independence. It translates specific hardware design of speech related devices into a virtual common set of functions
The Speech Agent is in general divided into two parts, the client part and the server part.
The client part exposes the API interface to the browser and uses the server part and its capabilities to perform all DSR tasks which can not be performed on the client.
For the transport of DSR parameters we envisage a DSR payload in Real Time Protocol (RTP) based DSR transport for Voice Recognition over IP when the VoIP protocols will be in future implemented on the mobile terminal.
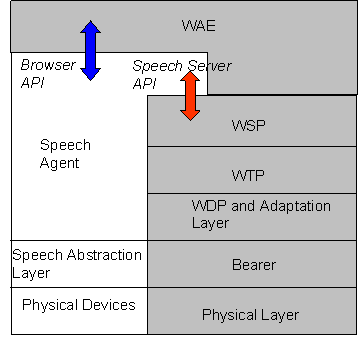
Fig. 3 Possible terminal implementation of a Speech Agent
Information generated by application running on server by means of textual, graphical and voice primitives will be presented to the user with a help of multi-modal browser placed on the terminal which is responsible for the MM interface.
Also the same way terminal accepts input from the user expressed as text, gestures and voice.
Because user actions and reactions must be synchronised and correctly associated with information stream on terminal, what in turn results in requirement, that primitives used as dialogue elements on terminal must be capable of all supported expression media, naturally in conformance with a purpose of particular primitive.
To make a terminal available for speech and text we propose that W3C extend a markup language and define new Speech Enabled (SE) language elements.
These new language elements should have all features currently required by particular element and they should have the following attributes additionally defined:
As the Speech Enabled dialogue element becomes focus the microbrowser processes it correspondingly to its input type. If dialogue element is speech enabled for input, Multi-modal Language (MML) Interpreter will activate feature extraction (FE) and the Speech Server receives voice data for further processing./p>
Furthermore, semantic and behaviour of new elements must be extended by capability to deal with a mix of text, gesture and voice.
Our most important interest concerns:
We would like to propose co-operation with ETSI STQ Aurora DSR Subgroup Applications & Protocols and co-ordination activities of W3C/WAP/Aurora, so that these three organisations supplement each other.
We are interested in deployment our research to the other in tasks mentioned above and look forward to answer questions and WAP/W3C visions concerning
D Pearce, "Enabling New Speech Driven Services for Mobile Devices: An overview of the ETSI standards activities for Distributed Speech Recognition Front-ends" Applied Voice Input/Output Society Conference (AVIOS2000), San Jose, CA, May 2000
Ben Milner, "Voice over IP, ETSI STQ Aurora DSR Subgroup "DSR Applications & Protocols".Partners Meeting, Prague, Czech Republic, July 2000