Initial version: 1999-11-12, Dan Brickley
danbri@w3.org
Status:
This is a work in progress and a personal view of the
technical relationship between RDF and older ideas from Web architecture.
It is an early release as an informal discussion document for
feedback from the RDF Interest Group. This is not a formal
publication of any working group, or of the W3C itself. Some typos
remain...
This document is provided as a background discussion motivating the WWW Proposal in RDF document. It was originally a sub-section of that work but grew too long and was reworked as a standalone commentary. As such, there is some duplication with that document which should be removed in any future versions.
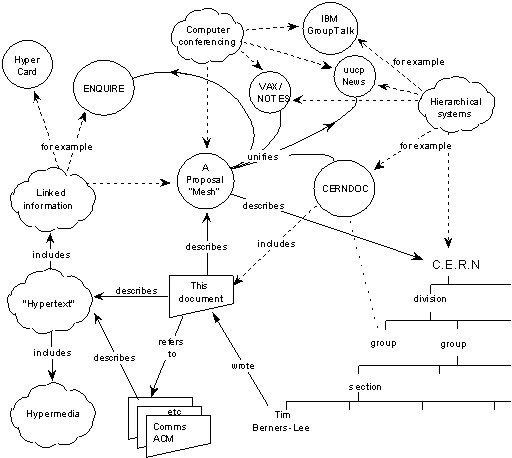
The original proposal of the WWW from 1989 included a figure showing how information about a Web of relationships amongst named objects could unify a number of information management tasks.
Having re-represented this data using RDF, what can we do with it that we couldn't before? The RDF pages list a number of query and logic oriented applications that suggest approaches to WWW knowledge management unavailable in 1989. For example, we can show a simple Javascript-based RDF Query demonstrator that queries this RDF database. (note that this is an in-progress work and currently functions in only a subset of Javascript/ECMAScript browsers).
The remainder of this document revisits some of the initial aims of the WWW, and connects these to the architecture adopted for the Resource Description Framework.
Note: The following discussion is only one interpretation of the relationship between the RDF data modeling system and the original system of knowledge management outlined in the WWW proposal. Readers are encouraged to consult the original WWW proposal before continuing, and to reach their own conclusions about this perspective on RDF.
A few relevant excerpts from the WWW proposal are reproduced here for convenience.
CERN is a wonderful organisation. It involves several thousand people, many of them very creative, all working toward common goals. Although they are nominally organised into a hierarchical management structure,this does not constrain the way people will communicate, and share information, equipment and software across groups.
The actual observed working structure of the organisation is a multiply connected "web" whose interconnections evolve with time. In this environment, a new person arriving, or someone taking on a new task, is normally given a few hints as to who would be useful people to talk to. Information about what facilities exist and how to find out about them travels in the corridor gossip and occasional newsletters, and the details about what is required to be done spread in a similar way. All things considered, the result is remarkably successful, despite occasional misunderstandings and duplicated effort.
A problem, however, is the high turnover of people. When two years is a typical length of stay, information is constantly being lost. The introduction of the new people demands a fair amount of their time and that of others before they have any idea of what goes on. The technical details of past projects are sometimes lost forever, or only recovered after a detective investigation in an emergency. Often, the information has been recorded, it just cannot be found.
This scenario is a familiar one. The challenges faced by CERN in 1989 are common to many companies and organizations in 1999. We now have widespread access to Internet information sources, typically accessed via the World Wide Web. However, the WWW has not yet provided a solution to the challenges it was initially proposed to address.
Word-of-mouth information is supplemented by online information sources, but access to these is still through relatively crude search systems. A common complaint about the WWW is that the 'search engines' which provide most users with information discovery facilities are somewhat crude. Searching for keywords and phrases amongst the Web pages of a large company or organization, let along the entire Web, will often result in a huge number of document being discovered. Often these bear no obvious relationship to the information needs of the user.
The original WWW proposal suggested that it should be possible to pose questions to an information management system and have them answered by a mechanism that understands something of the complex web of interelationships that exist between people, document, organizations and other entities.
Currently, users search for data on the Web by asking questions that are of the form: "which documents contain these words and phrases?"
The Resource Description Framework (RDF), following the original WWW design, suggests that we can do better than this. What questions might we want to ask the Web? A few were sketched in the WWW proposal...
The sort of information we are discussing answers, for example, questions like
- Where is this module used?
- Who wrote this code? Where does he work?
- What documents exist about that concept?
- Which laboratories are included in that project?
- Which systems depend on this device?
- What documents refer to this one?
With the exception of the last item on this wishlist ('which documents refer to this one'), the current Web (or Web search engines) does not allow such questions to be easily answered. There is however a close affinity between the model recently adopted in RDF and the structures described (but which were until recently unimplemented) in the WWW proposal. The WWW proposal notes that 'Linked Information Systems' can be applied to this set of problems...
In providing a system for manipulating this sort of information, the hope would be to allow a pool of information to develop which could grow and evolve with the organisation and the projects it describes. For this to be possible, the method of storage must not place its own restraints on the information. This is why a "web" of notes with links (like references) between them is far more useful than a fixed hierarchical system. When describing a complex system, many people resort to diagrams with circles and arrows. Circles and arrows leave one free to describe the interrelationships between things in a way that tables, for example, do not. The system we need is like a diagram of circles and arrows, where circles and arrows can stand for anything.
The proposal then goes on to describe a number of 'node' types and 'arrow' types such as might be used to represent diagrammatically the entities and relationships typical of a complex organisation such as CERN...
We can call the circles nodes, and the arrows links. Suppose each node is like a small note, summary article, or comment. I'm not over concerned here with whether it has text or graphics or both. Ideally, it represents or describes one particular person or object. Examples of nodes can be:
- People
- Software modules
- Groups of people
- Projects
- Concepts
- Documents
- Types of hardware
- Specific hardware objects
The proposal also lists a number of relationship types that might hold between these various types of thing. For some pair of entities A and B, they might stand in one of any number of relationships. It might be true that 'A'...
- depends on B
- is part of B
- made B
- refers to B
- uses B
- is an example of B
In doing so, the WWW proposal makes an interesting claim: that the complex mesh of information relating people, software, documents, concepts, organizations and other types of stuff could be understood through a very simple metaphor. The metaphor is that of a web of named relationships connecting uniquely identified things. This is, and not through coincidence, the exact same model for representing information as that adopted in RDF.
There are a number of different terminologies for talking about the same broad family of approaches to information management. The WWW proposal uses the terminology of 'node and arrow' diagrams, such as that reproduced above. Many in the database and data modeling communities talk of 'entity - relationship' modeling. RDF models are often represented graphically as 'node and arc' diagrams. In RDF contexts we also talk about the entities represented by nodes as 'Resources', and the relationships and attributes shown as arcs/arrows are called 'Properties'.
Despite terminological differences, RDF can be seen as the eventual formalization of this long-delayed component of the Web architecture. RDF is the W3C's recommended technology for describing 'data about data', or metadata. The notion of 'data about data' is somewhat confusing in a Web context. It is often useful to think about RDF models as a form of 'self describing' data. To understand this, it is important to appreciate the central role played by identifiers in the Web architecture.
"The Web works best when anything of value and identify is a first class object. If something does not have a URI, you can't refer to it, and the power of the Web is the less for that."
-- TimBL, Dec 1996
http://www.w3.org/DesignIssues/Axioms
On the Web, everything is a considered to be a 'resource', ie. a thing that can be identified, and through identification, be used. The vast 'nodes and arrows' diagram that constitutes the current World Wide Web consists mostly of documents connected by links whose type is relatively meaningless (the label is "href", which merely means "links to"). With the development of RDF and XML, we can anticipate a richer Web in which these nameable interrelationships are modelled in RDF and written down in XML syntax using RDF and X-Link.
The Web model is for all online resources to have unique identifiers. In addition, unique identifiers can be assigned to a variety of non electronic resources. The URI specification defines a convention for representing these identifiers as short textual strings; social and legal conventions define policies for assigning these identifiers to resources of all kinds: eg. documents, concepts and countless other entities. The URI system, like the Web itself, is designed to be extensible: as new ways of identifying objects (eg. DOIs, URNs etc) are proposed, Web URIs can accomodate these.
The crucial point is that every individual node, every type of node, and every type of arc in the 'nodes and arc' diagram be uniquely identifiable. The WWW familiar to users in 1999 is built on this principle: everything that exists to the Web is identified on the Web using URI identifiers. For example, a mailbox is identified with a 'mailto:' identifier, web pages are typically identified using 'http:' names. The power of the Web comes from this simple, almost trivial, principle: that unique identification is extremely useful for information management.
RDF is about self describing data in the sense that the principle of unique identification which underpins the Web is applied to the practice of modeling information. Although the RDF model of 'nodes and arcs' is almost unchanged from that outlined in the WWW proposal document, RDF takes things much further. By combining the principle of unique identification with the nodes and arrows representation system, we gain a powerfully simple perspective on information management.
We say that RDF's information model is self-describing because both the types of relationships (arrows, arcs) and the types of nodes that we see in node and arrow diagrams are themselves considered 'first class' objects, uniquely identifiable and therefore describable. We make the building blocks of our data modeling system into identifiable things on the Web by giving them URI names, so that different computer systems across the world can each make unambiguous use of the same types of nodes and arcs.
For example, when two objects are connected, as in the original diagram, by a 'wrote' arrow (eg. "Tim Berners Lee" --wrote--> "This document" ), the relationship we call "wrote" is given a Web identifier of its own. In 1999, we can use RDF and URIs to do this, and the XML data format to interchange such information between computers. The Dublin Core Metadata Initiative, for example, have defined a set of concepts such as 'Title', 'Creator', 'Description', 'Date'. So, instead of just writing the simple label 'creator', RDF uses a Web identifier: 'http://purl.org/dc/elements/1.0/Creator'. This gives us a node on the Web which represents the relationship 'Creator' that holds between creative agents (persons, organizations) and the works they create. Since we now have a URI for the notion of 'Creator', other communities can describe relationships between this and other nodes in the Web.
Why is this self-describing? Since the notion of Creator here is just another node or resource on the Web, RDF (ie. nodes and arrows) itself can be used to make statements about that thing. We might want to annotate it with a label, or textual description (in one or more natural languages). Or we might want to relate it to other resources. This is exactly what we see in the original WWW diagram: the node drawn as "Hypertext" is shown as having an "includes" arrow pointing to "Linked Information". This is a representation of the notion of a Linked Information Systems, such as the proposed WWW itself. A number of nodes are also drawn representing examples (or instances) of linked information systems, eg. ENQUIRE, Hypercard. Similarly, the node representing the category of "Hierarchical Systems" (examples being GroupTalk, UUCP/News, CERNDOC, VAX/Notes) is itself a "first class resource" in the diagram.
So... assuming we compose node-and-arc views of our diverse information systems, and assuming we give unique identifiers to everything that matters to our information management needs, what does this buy us?
If we give unique identifiers (URIs) to...:
...then we have an RDF-ready information system. We can use the universal syntax provided by XML to write down and exchange messages that contain information can be interpreted according to this model, and we can use the nodes-and-arcs model to provide a common 'interpretation strategy' for a wide range of information management scenarios.
If we want to ask for the identifiers of all things that are 'information systems' which are 'unified' by a system described by some named individual, we could couch this as a query consisting of URI identifiers and 'question marks' or variables.
For example (in a fictional syntax):
type(?X, InformationSystem), unifies(?X,?Y), describes(?Z,?X), wrote(?P,?Z).
or
type(?X, InformationSystem), unifies(?X,?Y), describes(?Z,?X), wrote("Tim Berners-Lee",?Z).
This is a computerish way of asking for groups of objects 'X','Y','Z','P', where P wrote Z, Z describes X, X 'unifies' Y, and X is an Information System. In our example from the original figure in the WWW proposal this would find a number of scenarios where nodes could be found that match this query. Written out in full, the answer to this query might look something like the following.
X= A Proposal: Mesh
Y= ENQUIRE
Z= 'This document' (ie. http://www.w3.org/History/1989/proposal.html)
P= Tim Berners-Lee
X= A Proposal: Mesh
Y= CERNDOC
Z= 'This document' (ie. http://www.w3.org/History/1989/proposal.html)
P= Tim Berners-Lee
X= A Proposal: Mesh
Y= VAX/Notes
Z= 'This document' (ie. http://www.w3.org/History/1989/proposal.html)
P= Tim Berners-Lee
X= A Proposal: Mesh
Y= UUCP/News
Z= 'This document' (ie. http://www.w3.org/History/1989/proposal.html)
P= Tim Berners-Lee
We have seen a few brief examples based around the image included in the original WWW proposal. The simple query presented here shows the way in which a question might be asked of a system that is organised around the 'nodes and arcs' model common to both the WWW proposal and RDF.
The RDF system does not yet include a specification for querying RDF models. However, a number of projects and applications exist that are exploring mechanisms for implementing RDF query. Most of them take a similar form to the above scenario; the only difference is that within the formal RDF model, URI identifiers must be used to unambiguously identify each node and each relationship-type (eg. 'creator' becomes 'http://purl.org/dc/elements/1.0/Creator'. In the simple query example above, we abbreviate these URIs for increased readability.
danbri@w3.org November 1999